

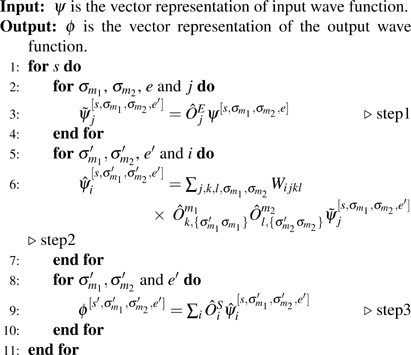
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Improved hybrid parallel strategy for density matrix renormalization group method
Cite this Article
Chen Fu-Zhou, Cheng Chen, Luo Hong-Gang. Improved hybrid parallel strategy for density matrix renormalization group method. Chinese Physics B, 2020, 29(7): 070202 
Permissions
Improved hybrid parallel strategy for density matrix renormalization group method
† Corresponding author. E-mail:
Project supported by the National Natural Science Foundation of China (Grant Nos. 11674139, 11834005, and 11904145) and the Program for Changjiang Scholars and Innovative Research Team in University, China (Grant No. IRT-16R35).
Abstract
We propose a new heterogeneous parallel strategy for the density matrix renormalization group (DMRG) method in the hybrid architecture with both central processing unit (CPU) and graphics processing unit (GPU). Focusing on the two most time-consuming sections in the finite DMRG sweeps, i.e., the diagonalization of superblock and the truncation of subblock, we optimize our previous hybrid algorithm to achieve better performance. For the former, we adopt OpenMP application programming interface on CPU and use our own subroutines with higher bandwidth on GPU. For the later, we use GPU to accelerate matrix and vector operations involving the reduced density matrix. Applying the parallel scheme to the Hubbard model with next-nearest hopping on the 4-leg ladder, we compute the ground state of the system and obtain the charge stripe pattern which is usually observed in high temperature superconductors. Based on simulations with different numbers of DMRG kept states, we show significant performance improvement and computational time reduction with the optimized parallel algorithm. Our hybrid parallel strategy with superiority in solving the ground state of quasi-two dimensional lattices is also expected to be useful for other DMRG applications with large numbers of kept states, e.g., the time dependent DMRG algorithms.
1. Introduction
Density matrix renormalization group (DMRG) is one of the most important numerical methods for low dimensional strongly correlated lattice models.[1–3] The ground state of a one-dimensional (1D) system can be obtained variationally by DMRG with extremely high efficiency and precision. After its invention for the real space lattice model, the application of DMRG has been extended to the momentum space[4,5] and quantum chemistry.[6–8] Besides the ground state algorithm, a serial of techniques, including the time-dependent and finite-temperature DMRG, are generalized and developed.[9–15] In addition, many novel quantum phases in two-dimensional (2D) interaction systems have been investigated by DMRG, e.g., stripe phase in high temperature superconductor[16–22] and quantum spin liquid.[23–25] However, in these extended applications, especially for the two and quasi-two dimensional problems, the computational cost of DMRG increases dramatically for the convergent results. These lead to great challenges to the computing and storage capabilities of the contemporary computers.
Nowadays, variety of optimized methods have been proposed to reduce the computational cost of DMRG, for example, targeting the states in smaller Hilbert subspace in the presence of multiple symmetries,[5,26,27] the dynamical block state selection approach,[28,29] one-site sweep strategy,[30,31] and good initial wave function for the eigensolver.[32] On the other hand, to take full advantages of the advanced high-performance computing technique and further shorten the time cost of DMRG, there have been different parallelization strategies on high-performance computers, e.g., real space parallel DMRG,[33] shared/distributed-memory multi-core parallelization,[34,35] and parallelization on heterogeneous architectures.[36,37] Especially, the heterogeneous architectures employing both central processing unit (CPU) and graphics processing unit (GPU) have potential to significantly improve the efficiency, since the floating-point performance and memory bandwidth of GPU are usually many times higher than the host part.
Along this direction, a pioneer work has implemented DMRG on the hybrid CPU–GPU architecture, and achieved considerable speedup.[36] However, this implementation is based on the two-subblock configuration, the memory cost of which is d2 (d is the local Hilbert space dimension of a single site) times larger than that of the four-subblock expression. Recently, we propose a new hybrid CPU–GPU parallel strategy with the Hamiltonian expressed by the operators of four subblocks, which greatly reduces the GPU memory cost.[37] In our implementation, one is able to use much larger number of DMRG kept states (upto 104) to investigate more complex systems, such as spinfull fermions on the quasi-two-dimensional lattice.
In our previous work, the hybrid strategy focuses on the diagonalization of the Hamiltonian, which is the most time-consuming part for the DMRG procedure with large number of kept states. According to a dynamical load balancing strategy, the matrix and vector operations in diagonalizing the Hamiltonian are distributed to CPU and GPU, and are performed using parallel MKL[38] and CUBLAS[39] subroutines, respectively. While these libraries generally achieve high performance in most cases, they are not always the best choice. For example, we get low performance when using these parallel subroutines for small matrix and vector operations. Therefore, in this work we improve our parallelization strategy by optimizing the diagonalization part. On the host, when acting the Hamiltonian on the wavefunction, we adopt OpenMP application programming interface[40] and sequential MKL subroutines, instead of parallel MKL subroutines. On the GPU, for vector operations in acting the Hamiltonian on the wavefunction, we use our own subroutines which gets higher bandwidth for linear combination of vectors. In addition, the previous DMRG truncation procedure with lots of matrix operations is only performed by the CPU. In the current work, we perform most of these operations on the GPU to further reduce the total computational time.
This paper is organized as follows. In Section
2. The DMRG method and benchmark model
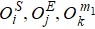
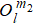
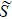
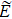
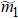
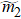
1 .
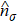
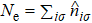
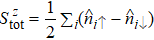
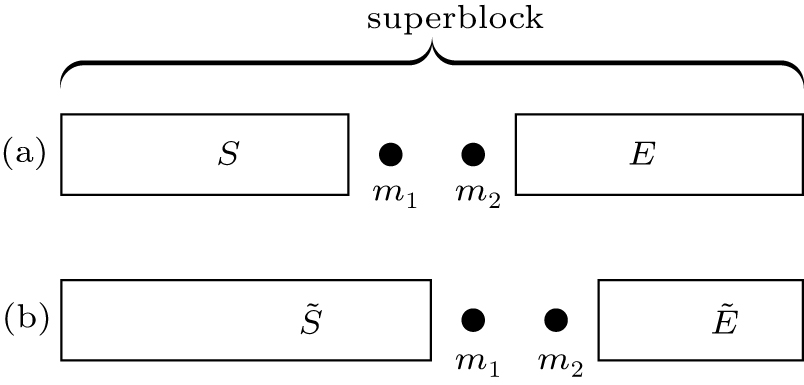
A DMRG routine for finite lattice usually contains 1) infinite-system DMRG with a small number of states to produce a good initial wavefunction, and 2) a few finite-system DMRG sweeps to get the convergent result. For the quasi-two-dimensional lattice models, finite DMRG sweeps take most of the computational time. In each sweep, the wavefunction is updated through the lattice system from left to right, and then back to the left side. Without loss of generality, we briefly introduce one DMRG step with sweeping through the lattice system from left to right as an example. In our implementation, the lattice system is partitioned into four subblocks (see Fig.
 | Fig. 1. Schematic one-step procedure of finite-system DMRG sweeps in four-subblock formulation. |
A wave function |ψ〉 can be expressed in four-subblock basis as


To demonstrate the performance of our improved implementation, we apply it to get the ground state of the 4-leg Fermi Hubbard ladder with the next-nearest hopping, which is defined as
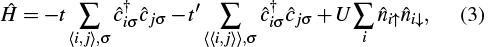
In our implementation, we employ these two good quantum numbers to reduces the computational and memory cost. In this paper, we set the nearest hopping t = 1 as the energy scale, and fix the next-nearest hopping t′ = 0.25 and the Coulomb repulsion U = 6. For the performance benchmark, we focus on the 4-leg ladder with leg-length Lx = 16 and particle filling 7/8. The cylinder geometry is adopted, with open and periodic boundaries along the leg and rung, respectively. For all calculations, we take 5 sweeps to obtain the convergent energy.
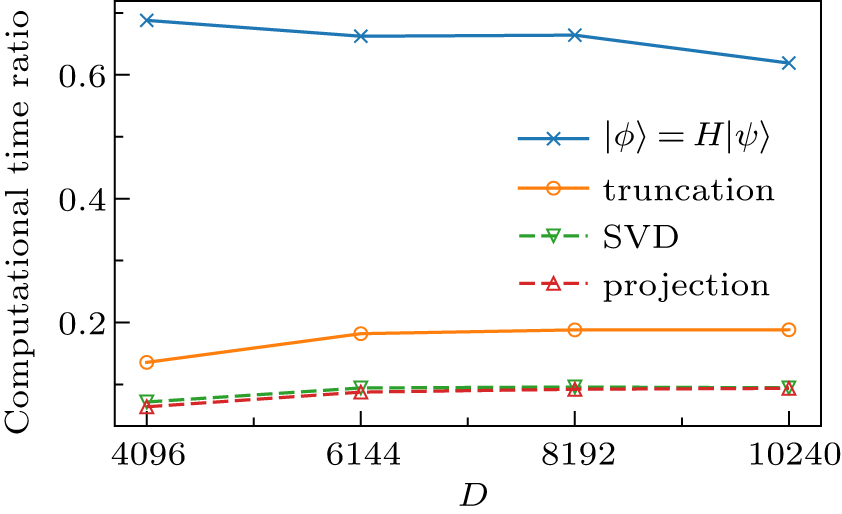
Employing the previous hybrid parallel strategy[37] on the next-nearest hopping Hubbard ladder, we get the computational time proportion of several computing sections, as shown in Fig.
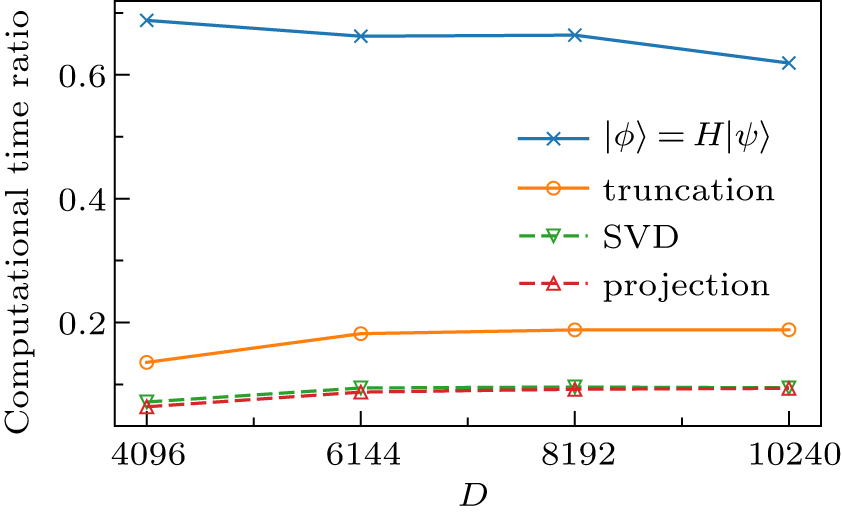 | Fig. 2. The computational time ratio to the total time cost for the most time-consuming parts. Applying the Hamiltonian to the wavefunction (|ϕ〉 = H|ψ〉, denoted by ×) is the core operation for diagonalizing the Hamiltonian. The truncation procedure (°) contains diagonalizing the reduced density matrix (▽) and projecting the operator on the new basis (Δ). The former can be considered as the singular value decomposition (SVD) of the superblock wavefunction. |
3. Hybrid parallel strategy
3.1. The diagonalization of the Hamiltonian
Among variety of subspace iterative projection methods for large-scale sparse matrix, we choose Davidson method[41] to diagonalize the Hamiltonian. In each iteration one needs to perform the action of the Hamiltonian on the wavefunction, which contributes most of the computational complexity. In practice, it is unnecessary to construct the matrix representation of the Hamiltonian. Instead, we apply the Hamiltonian directly to the wave function based on operators in subblocks, as shown in Algorithm 
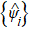


| Algorithm 1 Acting the Hamiltonian (see Eq. ( |
To achieve high total performance, we partition the action |ϕ〉 = H|ψ〉 into two parts according to the subspaces of subblock S (see line 1 in Algorithm
Lots of large vector operations are executed on the GPU for DMRG calculations with a large number of kept states. In our previous strategy, the operations about one output subvector are performed using CUBLAS subroutines in one CUDA stream, and different subvectors are calculated in multiple CUDA streams concurrently. This parallel scheme is good for steps 1 and 3 in Algorithm
| Algorithm 2 The kernel for step 2 in Algorithm |
The performance improvement of our new parallel strategy in acting the Hamiltonian on the wavefunction is displayed in Fig.
 | Fig. 3. The relative performance improvement of Algorithm |
3.2. The optimization of the truncation procedure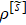
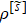
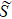
After the diagonalization of the Hamiltonian, the number of states of the new subblock 


In the projection procedure, we obtain the new basis set by keeping states corresponding to the largest D eigenvalues of the whole reduced density matrix. Benefit from good quantum numbers, the projection for each subspace is independent. In subspace 

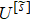
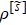
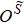


As shown in Fig.
4. Result and benchmark
To test the performance of our optimized parallel strategy, we apply it to calculate the ground state of the model (
| Table 1. The ground state energy per site E0/L. L is the total site number of the lattice. CPU–GPU denotes our results. . |
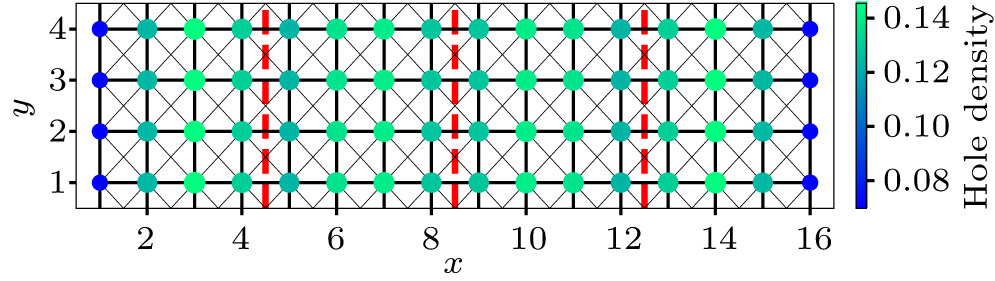
We also compute the charge density 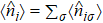

 | Fig. 4. The hole density on each site. Hole density is represented by both the area and the color depth of the disk. Black solid lines denote hopping, and red dashed lines represent the positions of maximum hole density. Here D = 10240. |
For different DMRG kept states D, we set the total computational time of our previous strategy as the unit, and demonstrate the performance improvement of each optimized section by showing the relative computational time reduction, as displayed in Fig.
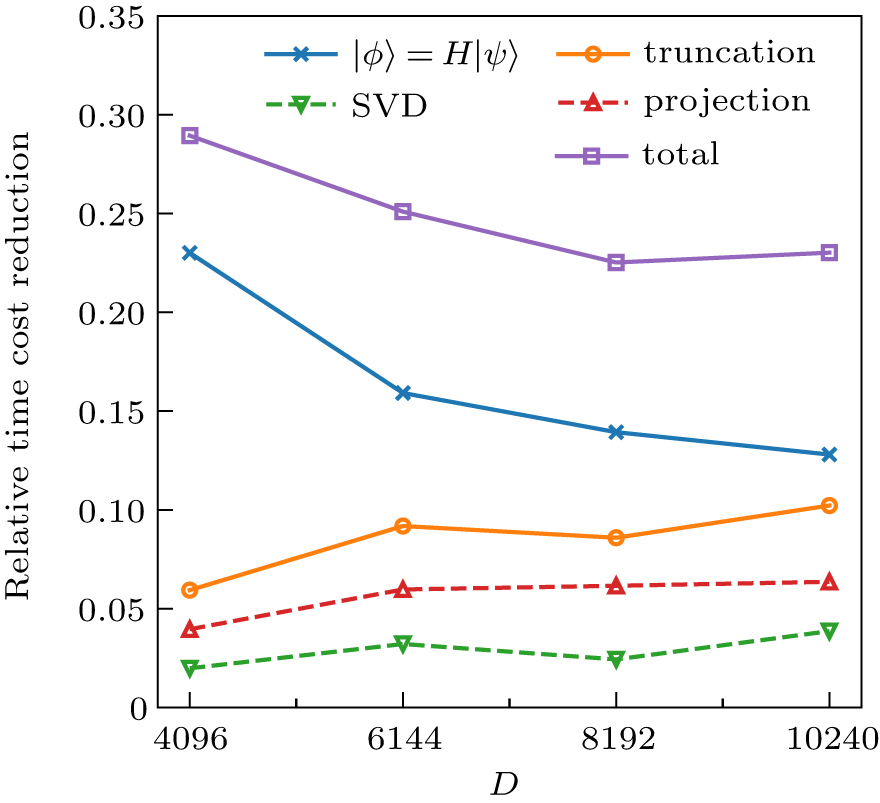 | Fig. 5. The relative time cost reduction of different computing sections compared to the total computational time in our previous work. Truncation procedure (°) contains SVD (▽) and projection (Δ). |
In our hybrid parallel strategy, we have considerably improved the performance of matrix and vector operations in DMRG calculation of the quasi-2D Hubbard model. Meanwhile, in the procedure of acting the Hamiltonian on the wave function (see Algorithm
5. Conclusion
In this paper, based on our previous work, we propose an optimized parallel scheme of DMRG method on the hybrid CPU–GPU architecture. Applying it to solve the ground state of a 4-leg Hubbard model with next-nearest hopping, we obtain the charge stripes usually being observed in high temperature superconductors, and demonstrate the performance improvement. Compared to the previous strategy, both the diagonalization and the truncation procedure are optimized, and these optimizations significantly reduce the total computational time in the DMRG calculation. Our results indicate the advantage of the new hybrid parallel strategy and the importance of high performance computing in strongly correlated algorithms. We expect our hybrid parallel strategy benefits DMRG applications with large number of kept states, for example, ground state DMRG for quasi-2D lattice models and time-dependent DMRG methods.
Reference
| [1] | |
| [2] | |
| [3] | |
| [4] | |
| [5] | |
| [6] | |
| [7] | |
| [8] | |
| [9] | |
| [10] | |
| [11] | |
| [12] | |
| [13] | |
| [14] | |
| [15] | |
| [16] | |
| [17] | |
| [18] | |
| [19] | |
| [20] | |
| [21] | |
| [22] | |
| [23] | |
| [24] | |
| [25] | |
| [26] | |
| [27] | |
| [28] | |
| [29] | |
| [30] | |
| [31] | |
| [32] | |
| [33] | |
| [34] | |
| [35] | |
| [36] | |
| [37] | |
| [38] | |
| [39] | |
| [40] | |
| [41] | |
| [42] | |
| [43] |