









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Enhancing convolutional neural network scheme for rheumatoid arthritis grading with limited clinical data
Cite this Article
Tang Jian, Jin Zhibin, Zhou Xue, Zhang Weijing, Wu Min, Shen Qinghong, Cheng Qian, Wang Xueding, Yuan Jie. Enhancing convolutional neural network scheme for rheumatoid arthritis grading with limited clinical data. Chinese Physics B, 2019, 28(3): 038701 
Permissions
Enhancing convolutional neural network scheme for rheumatoid arthritis grading with limited clinical data
† Corresponding author. E-mail:
Project supported by the National Key Research and Development Program of China (Grant No. 2017YFC0111402) and the Natural Science Funds of Jiangsu Province of China (Grant No. BK20181256).
Abstract
The gray-scale ultrasound (US) imaging method is usually used to assess synovitis in rheumatoid arthritis (RA) in clinical practice. This four-grade scoring system depends highly on the sonographer’s experience and has relatively lower validity compared with quantitative indexes. However, the training of a qualified sonographer is expensive and time-consuming while few studies focused on automatic RA grading methods. The purpose of this study is to propose an automatic RA grading method using deep convolutional neural networks (DCNN) to assist clinical assessment. Gray-scale ultrasound images of finger joints are taken as inputs while the output is the corresponding RA grading results. Firstly, we performed the auto-localization of synovium in the RA image and obtained a high precision in localization. In order to make up for the lack of a large annotated training dataset, we performed data augmentation to increase the number of training samples. Motivated by the approach of transfer learning, we pre-trained the GoogLeNet on ImageNet as a feature extractor and then fine-tuned it on our own dataset. The detection results showed an average precision exceeding 90%. In the experiment of grading RA severity, the four-grade classification accuracy exceeded 90% while the binary classification accuracies exceeded 95%. The results demonstrate that our proposed method achieves performances comparable to RA experts in multi-class classification. The promising results of our proposed DCNN-based RA grading method can have the ability to provide an objective and accurate reference to assist RA diagnosis and the training of sonographers.
1. Introduction
Rheumatoid arthritis (RA) is one of the most common autoimmune diseases, which is characterized by pain, swelling, and stiffness of the joints, affecting almost 1% of the population around the world.[1–4] Detecting the diseased finger joint region of RA patients and quantifying its severity in progressive stages are important for diagnosis, treatment decisions, and prediction of disease progression. Clinically, RA severity is assessed using the gray-scale-evaluated synovial hyperplasia score, which is a four-grade semi-quantitative criterion.
Most of the related studies about RA severity grading concentrate on the detection of finger joints or the identification of bone erosions on the dataset of x-ray images instead of ultrasound images. Sungmin Lee et al. proposed a novel approach for the detection of all finger joints from hand radiograph images.[5] Seiichi Murakami et al. proposed a method to automatically identify bone erosions on hand radiographs with segmentation using the multiscale gradient vector flow snakes algorithm and an identification classifier.[6] Since ultrasound imaging is a more popular RA detection approach than x-ray computed tomography (CT) in RA grading, the research of detecting and quantifying the severity of RA with ultrasound images is recognized as helpful to clinical diagnosis.
The assessment of RA can be considered as an image classification[7,8] problem. Previous automatic medical image analysis methods are based on low-level pixel processing and mathematical modeling, such as region growing and edge detection.[9] Later, statistical classifiers and analysis methods have started to use data training with handcrafted features, such as the histogram of oriented gradient (HOG)[10] and the scale-invariant feature transform (SIFT).[11] The critical step in these methods is the extraction of discriminant features, which is difficult to be inducted from the processed images. Recently, deep learning algorithms represented by the convolutional neural network (CNN)[12,13] have made significant breakthroughs in medical image analysis. Studies have demonstrated that deep learning algorithms outperform traditional statistical learning methods, achieving high accuracy and stability.[14]
However, training a CNN from scratch requires an enormous amount of training data while the process of annotating medical images is time consuming, requiring medical specialists.[15] The sizes of medical datasets are usually at a level of hundreds or thousands, which is much smaller than those million-level datasets in computer vision. The lack of annotated medical data is a crucial challenge for the application of deep learning in medical image analysis, thus inspiring the employment of transfer learning. Essentially, transfer learning aims to extract knowledge from one or more source tasks and apply it to a new target task. The main transfer learning strategy for deep neural network training is using a pre-trained network (typically on natural image datasets such as ImageNet[16]) as a feature extractor and fine-tuning the pre-trained network on the target medical dataset. This strategy has been widely applied in the deep learning for medical image analysis.
In this study, we proposed an enhanced CNN-based grading scheme to solve the automatic grading of RA ultrasound images. The rest of the paper is organized as follows. In Section
2. Methods
2.1. Data acquisition
The RA ultrasound images were acquired from the Philips IU22 and the Philips EPIQ 7 ultrasound scanners in Nanjing Drum Tower Hospital by two professional clinicians, employing the high-frequency transducer (12–5 MHz) seen in Fig.
 | Fig. 1. The acquisition process of RA ultrasound images. |
 | Fig. 2. The acquisition process of MCP images and PIP images. The MCP joint is the joint between metacarpal phalangeal bone and proximal phalange bone. The PIP joint is the joint between proximal and intermediate phalanx. |
The gray-scale-assessed synovial hyperplasia scoring system defines four grades to classify RA severity from the ultrasound images.[3] Grade 0 corresponds to no synovial thickening. Grade 1 corresponds to the minimal synovial thickening that fills the angle between the periarticular bones without bulging over the line linking tops of the bones. Grade 2 corresponds to the moderate synovial thickening that bulges over the line linking tops of the periarticular bones but without extension along the bone diaphysis. Grade 3 corresponds to the severe synovial thickening that bulges over the line linking tops of the periarticular bones with extension to at least one of the bone diaphysis, as shown in Fig.
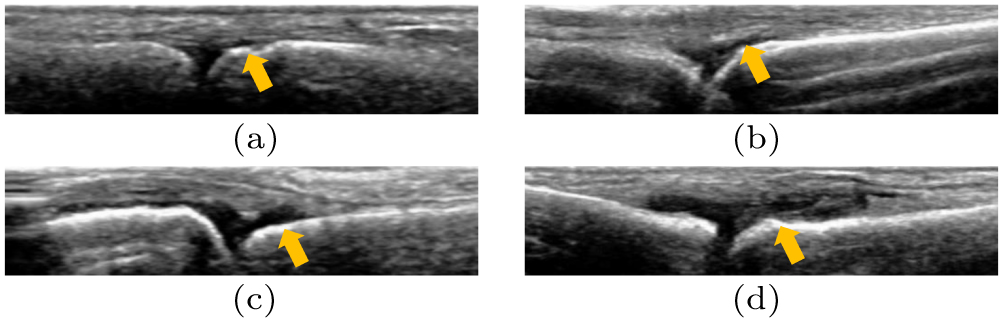 | Fig. 3. Synovial changes on ultrasonography: (a) Grade 0, (b) Grade 1, (c) Grade 2, and (d) Grade 3. |
2.2. Data augmentation
We employed two RA ultrasound image datasets for the network training. One contained 662 RA images of MCP joints while the other one contained 315 images of PIP joints. The samples were split into 80% training and 20% test sets.
Hundreds of ultrasound images are not sufficient for the training of CNN and may lead to a serious over-fitting problem.[17] Therefore, we preformed data augmentation on training samples to improve the generalization ability of the network. Data augmentation is essentially expanding the training set through different kinds of transformations which should preserve the data label. The data augmentation we took mainly included the following three methods.
2.2.1. Image crops
The size of original ultrasound images offered by clinicians is 1024×768. Through careful observation, we found that the region of interest (ROI) around the finger joint could always be included in a 520×120 rectangle. We cropped four 520×120 ROI areas from the original images as shown in Fig.
 | Fig. 4. The process of data augmentation. |
2.2.2. Adding Gaussian noises
We added Gaussian noise to the cropped images as a common data augmentation method. Related studies, such as Refs. [18] and [19], employed this method to generate sufficient training examples and avoid the over-fitting problem.
2.2.3. Histogram equalization
We performed histogram equalization on the cropped images as another choice of augmentation which enhances the contrast of the processed images. Histogram equalization is also an effective approach for image augmentation which was adopted in the related studies such as Refs. [20] and [21].
By data augmentation, the size of training sets was increased by twelve times (see Fig.
| Table 1. Statistics on MCP & PIP datasets (the slash character refers to the split of training set and test set). . |
2.3. Localization of synovium
where pu is the predicted probability of an anchor being an object and Lcls is the log loss for true class u. The localization class Lloc is defined over both the bounding box ground truth v = (vx, vy, vw, vh) and the predicted bounding box coordinates
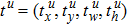
for class u. It is noted that the background class is labeled as u = 0 and hence Lloc is ignored for background anchors. Lcls is normalized by the mini-batch size Ncls and Lloc is normalized by the number of anchor locations Nreg. The balancing parameter λ is set to 10 by default. We emphasize that the bounding box regression loss is calculated with the smoothL1 function which is more robust to outliers than the commonly used L2 loss.
To implement the auto localization of the synovium, we employed faster R-CNN,[22] which is a state-of-the-art object detection method. It consists of two modules, which are the region proposal network (RPN) and the fast R-CNN network[23] (see Fig.
 | Fig. 5. The network structure of faster R-CNN. |
Anchors are applied in the RPN to detect objects of different scales and aspect ratios. An anchor is a bounding box centered at the sliding 3 × 3 window. Each anchor is denoted as positive or negative depending on whether it contains an object. Each sliding position in the convolutional feature map corresponds to k anchors (by default k = 9). For a convolutional feature map of a size W × H, there will be W × H × k region proposals (see Fig.
 | Fig. 6. The illustration of sliding window. |
The faster R-CNN employs a multi-task loss on each anchor to jointly train for classification and bounding box regression,
 |
 |
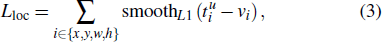 |
 |
2.4. Grading of rheumatoid arthritis
where loss1 and loss2 are the losses of auxiliary classifiers in the intermediate layers weighted by 0.3 and loss3 is the loss of the final layer. Each loss function is calculated in the form of cross-entropy
where fj is the j-th element in the output vector of the final fully-connected layer, yi is the label of the input image xi, and wt is the weight matrix of the network. The softmax function squashes the input vector to a vector of values between zero and one that sum to one.
We adopted a 22-layer GoogLeNet inception V1 network[25] to implement the RA severity grading. GoogLeNet is characterized by its inception module which is designed to use the available dense components to approximate an optimal local sparse structure in CNN. As shown in Fig.
 | Fig. 7. Structure of the inception module. |
To alleviate the vanishing gradient problem,[26,27] two extra losses are added in the intermediate layers of the network with a discount weight during the training process. This implementation is based on the fact that features from the intermediate layers are also discriminative. The total loss of the network is calculated as
 |
 |
 |
Motivated by the transfer learning strategy, we employed the GoogLeNet models pre-trained on ImageNet, which is a large-scale image database with millions of annotated natural images. Then we fine-tuned it on our own MCP&PIP datasets. As Fig.
 | Fig. 8. The illustration of fine-tuning. |
3. Experiments and discussion
3.1. Assessment method
The five subsets were obtained by stratified sampling to maintain the consistency of data characteristics. Each time we used the union of four subsets as the training set and performed data augmentation on it and took the remaining one as the test set. Through such methods, we obtained five groups of training/test sets. The final result was averaged over all five test results (see Fig. 9 ).
where the TP, FP, TN, FN are explained in Table 2 .
To ensure the stability and reliability of the testing results, we preformed five-fold cross validation in the synovium localization and RA severity grading for all datasets (MCP&PIP: Grade 0 to Grade 3, Grade 0 vs. Grade 1/2/3, Grade 1 vs. Grade 3). For each dataset, we split the whole dataset D into five mutually exclusive subsets with equal size, which means
 |
 | Fig. 9. The diagram of five-fold cross validation. |
To quantitatively evaluate the performance of our grading model, we calculated four common machine-learning assessment metrics: accuracy, precision, recall, and F1measure. These metrics can be calculated by the prediction result of all tested images. Taking the binary classification problem of normal people and the patients with synovial thickening (Grade 0 vs.
 |
 |
 |
 |
| Table 2. The explanation of TP, FP, TN, and FN. . |
3.2. Experiments
3.2.1. Localization of synovium
where Bp is the predicted bounding box while Bgt is the ground truth bounding box. Correct detections must have an IOU over 0.5.
To perform synovium localization, we took the original 1024×768 images of MCP&PIP as the input of the faster R-CNN. The choice for such datasets is to provide guidance for clinicians on recognizing the synovium area from the original images. The size of the MCP dataset was 662 while the size of the PIP dataset was 315. We chose ZFNet as the basic network to extract the features shared by the RPN and the fast R-CNN. The employed ZFNet model was pre-trained on ImageNet. We chose the four-step alternating training strategy to jointly train the RPN and fast R-CNN network on Caffe framework.[28]
All experiments were performed on the HP xw8600 workstation equipped with NVIDIA Quadro K5200. The operation system is ubuntu 16.04 while the CUDA version is 7.5. Each training of the faster R-CNN took about one hour.
We took the average precision (AP) as a quantitative measure for the detection of synovium, which is the sum of the area under the precision-recall curve. Detections are considered true or false positives based on the intersection over union (IOU)
 |
3.2.2. Grading of rheumatoid arthritis
We employed the Caffe deep learning framework to implement and train the GoogLeNet. The pre-trained model was downloaded from the Caffe Model Zoo. We renamed the three fully-connected layers while the output number was changed from 1000 to our own grading number. Specifically, the output number for Grade 0 to Grade 3 classification is 4, while the output numbers for Grade 0 vs. Grade 1/2/3 classification and Grade 1 vs. Grade 3 classification are 2. We modified the basic learning rate of the whole network from 0.01 to 0.001 to match our training dataset. However, for the fully-connected layers, we kept the learning rates unchanged to fit our own RA severity grading rapidly. Then we started training with the pre-trained Caffe model files. We chose stochastic gradient descent (SGD) as the optimization method to minimize training loss with back-propagation.[29]
To evaluate the effect of data augmentation and fine-tuning with the pre-trained model, we performed contrast experiments for the Grade 0 to Grade 3 classification, Grade 0 vs. Grade 1/2/3 classification classification (normal vs. abnormal), and Grade 1 vs. Grade 3 classification (minimal vs. severe) on MCP&PIP datasets, which are without augmentation, without fine-tuning, performing both techniques, and preforming neither technique. The running environment was the same as the training of the faster R-CNN and each training of GoogLeNet took about 2.5 hours.
3.3. Experimental results and discussion
3.3.1. Localization of synovium
We first discuss the final detection results averaged by five-fold cross validation. The average precision (AP) of MCP is 94.37% while the average precision of PIP is 91.57%. Two detection results are displayed in Fig.
 | Fig. 10. The detected synovium in (a) MCP and (b) PIP ultrasound images. |
3.3.2. Grading of rheumatoid arthritis
The test results averaged by five-fold cross validation are shown in Tables
| Table 3. The classification accuracy of MIP/PIP datasets under the circumstance of non-augmentation & non-fine-tuning, non-augmentation & fine-tuning, augmentation & non-fine-tuning, and augmentation & fine-tuning. The slash character is used to distinguish between MCP dataset and PIP dataset and the standard deviations are given in parentheses. . |
| Table 4. The precision, recall, and F1-measure of MCP/PIP datasets under the circumstance of augmentation & fine-tuning. The slash character is used to distinguish between MCP dataset and PIP dataset and the standard deviations are given in the parentheses. . |
It is shown that CNN does not perform well without any preprocessing. In this case, the grading accuracy is basically not higher than 90%. After we employed the data preprocessing and transfer learning techniques, the four-grade classification accuracy exceeded 90% while the binary classification accuracies of Grade 0 vs. Grade 1/2/3 and Grade 1 vs. Grade 3 both exceeded 95%. Such comparison results prove that data augmentation and loading of pre-trained models for fine-tuning are capable of boosting the generalization ability of CNN to increase classification accuracy.
We also assessed the contributions of the network performance promotion. Data augmentation plays a crucial role by boosting the initial accuracy by 5% in most cases while the pre-training & fine-tuning only boosts the initial accuracy by less than 5%. The Grade 1 vs. Grade 3 classification shows the highest accuracy as the contrast between minimal and severe synovium thickening is quite obvious. The two binary classification accuracies are also higher than the four-grade classification accuracy. The precision, recall, and F1-measure of each augmented dataset after fine-tuning also exceed 90%, which indicate the feasibility and effectiveness of our proposed method from other aspects.
The classification results of five tests tend to be stable overall. As the dataset size of Grade 1 vs. Grade 3 is smaller than the other two, so its standard deviations look bigger.
4. Conclusions
Quantifying RA severity has always been a difficult diagnostic problem due to its semi-quantitative score criterion. Based on the CNN algorithm, we proposed an automatic classification method of RA ultrasound images. Firstly, we performed the auto-localization of the synovium lesion area along the finger joints. The detection results showed fine visual effects with an average precision exceeding 90%, albeit without making classifications in the finest steps. Then we implemented the RA severity grading. The four-grade classification accuracy exceeded 90% while the binary classification accuracies exceeded 95%. The stability and high accuracy of CNN provide a possible solution to such a classification problem of semi-quantitative criterion and also make up for the inconsistency of diagnosis made by clinicians. Most critically, the combination of data augmentation and transfer learning techniques employed in our work alleviated the problem of lacking large, annotated datasets, a frequently-encountered problem in medical image analysis. This reveals the promising application value of our proposed CNN-based RA grading method in assisting professional clinicians to diagnose.
Future work will focus on the detection of joint effusion and the blood flow grading of synovial joints. We will keep on increasing the training samples with the cooperation of sonographers and prepare to try other data augmentation methods such as generating new samples with generative adversarial networks (GAN). In addition, the research can be extended to other joints such as those of the wrist, ankle, metatarsophalanges, and elbow.
Reference
| [1] | |
| [2] | |
| [3] | |
| [4] | |
| [5] | |
| [6] | |
| [7] | |
| [8] | |
| [9] | |
| [10] | |
| [11] | |
| [12] | |
| [13] | |
| [14] | |
| [15] | |
| [16] | |
| [17] | |
| [18] | |
| [19] | |
| [20] | |
| [21] | |
| [22] | |
| [23] | |
| [24] | |
| [25] | |
| [26] | |
| [27] | |
| [28] | |
| [29] |