{kind=link}
{kind=link}
{kind=link}
{kind=link}
Image encryption using random sequence generated from generalized information domain
[Zhang Xia-Yan1, Zhang Guo-Ji2, †,  , Li Xuan3, Ren Ya-Zhou4, Wu Jie-Hua1]
, Li Xuan3, Ren Ya-Zhou4, Wu Jie-Hua1]
, Li Xuan3, Ren Ya-Zhou4, Wu Jie-Hua1]
|
|


† Corresponding author. E-mail:
A novel image encryption method based on the random sequence generated from the generalized information domain and permutation–diffusion architecture is proposed. The random sequence is generated by reconstruction from the generalized information file and discrete trajectory extraction from the data stream. The trajectory address sequence is used to generate a P-box to shuffle the plain image while random sequences are treated as keystreams. A new factor called drift factor is employed to accelerate and enhance the performance of the random sequence generator. An initial value is introduced to make the encryption method an approximately one-time pad. Experimental results show that the random sequences pass the NIST statistical test with a high ratio and extensive analysis demonstrates that the new encryption scheme has superior security.
With the development of information technology and the Internet, digital images have been widely used in many areas. The security of images in some special areas, such as health systems, military systems, geographic information systems (GIS) or images of business and personal privacy has become an important issue. Image encryption is different from text encryption due to some inherent features, such as bulk data capacity, high correlation among pixels and high redundancy. Thus, most conventional ciphers, such as DES (data encryption standard), IDEA (international data encryption algorithm), AES (advanced encryption standard), etc. are not suitable for image encryption especially in real time encryption.
There is a wide range of algorithms used in image encryption such as cellular automaton (CA),[1–3] DNA computing,[4–6] and chaotic systems. Chaotic systems have several significant features favorable to secure communications, such as ergodicity, sensitivity to initial conditions, control parameters and random-like behavior, which can be connected with some conventional cryptographic properties of good ciphers, such as confusion and diffusion. After Matthews proposed the chaotic encryption algorithm in 1989,[7] increasingly research of image encryption technology is based on chaotic systems.
Many chaos-based cryptography schemes have shortcomings. One is the short cycle length resulting from the finite precision of computers which makes various attacks possible.[8,9] To extend the cycle length of chaotic systems, some chaotic stream ciphers utilized dual chaotic systems or hyper chaotic systems.[10–13] Another problem is that the key stream generated by the chaotic map is completely dependent on the secret key and remains unchanged to any plain image, which is insecure against chosen plain text attack.[14] In Ref. [14], a new block encryption scheme was proposed by combining circular bit shift and XOR operations based on iterating a chaotic map. Li et al.[15] showed that there are some security defects in such a scheme (proposed in Ref. [14]) and most elements in the underlying chaotic pseudorandom bit sequence can be obtained by a differential known plain text attack using only two known plain texts. To solve this problem, some approaches that try to make the encryption process or the key stream related to the plain image were proposed. In Ref. [16], a chosen plain text attack of Ref. [14] was presented because of the plain text-independent key stream, and an improvement was suggested by using a ciphertext feedback mechanism. Xu et al.[17] analyzed and improved the above algorithms by using Chen chaotic system instead of a logistic map for better random number sequence and setting the parameter of the Chen map using the last one byte of encrypted plain text after every iteration. Wang et al.[18] proposed an algorithm using a logistic map in which the shuffling and diffusion are performed simultaneously and the chaotic maps' states are altered according to the encrypted pixel. Zhang et al.[19] employed a plain text feedback in permutation using the max and sum of the pixel value of the plain image and a plaintext/ciphertext feedback in diffusion. The permutation process behaves in a “one-time pad” manner and the diffusion process is sensitive to changes of plain image. Chen et al.[20] presented an image encryption scheme with a dynamic state variables selection mechanism. The state variables generated from chaotic systems are distributed to each pixel dynamically and pixel-relatively in both permutation and diffusion procedures. Dong[21] proposed a color image encryption scheme using one-time keys based on coupled chaotic systems. It employed secure hash algorithm 3 (SHA-3) combined with the initial keys to generate the new keys which would change in each encryption process.
The permutation–diffusion structure[22] is the most common and effective encryption architecture and has become the basis of many chaotic image encryption schemes since Fridrich developed a chaos-based image encryption scheme of this structure in 1998,[23] which was first cryptanalyzed in Ref. [24] using a chosen-ciphertext attack. It is composed of two steps: pixel permutation and diffusion. In the permutation process, the positions of image pixels are changed. In the diffusion process, the pixel values are modified sequentially so that a tiny change for one pixel can spread out to almost all pixels in the whole image. Zhang et al.[25] used a skew tent map to generate random sequences then sort the sequence to get index sequence as a P-box with the same size of the plain image which totally shuffled the plain image. Zhang et al.[26] sorted random chaotic sequences to get the index sequence as small permutations and then constructed large permutation from the small permutations and totally shuffled the plain image. General permutation-only image encryption algorithms have been quantitatively cryptanalyzed[27] and one round permutation–diffusion is not secure enough especially against chosen plain text attack.[28] Therefore, many image encryption algorithms employ the permutation–diffusion process by two rounds or more.
Zhang et al.[29] proposed a random number generator based on discrete trajectory transform in generalized information domain (RGDG) which has superior randomness. RGDG has a time-related initial value so that it can generate different random sequences every time. In this paper, our main contribution includes: 1) We introduce a new factor called drift factor (DF) and develop an improved algorithm of RGDG called RGDG-DF, which has an increased speed. 2) RGDG has an initial value IV = {t,r,u} where t is system time, r is a system random number and u is user’s personalized input. In RGDG-DF, IV = {ST, SI, UI}, where ST is system time, SI is system identifier that is unique, such as hard disk number of the machine and UI is user input. 3) IV is employed in RGDG-DF in a feedback mechanism. In every encryption process, IV is different so that random sequences generated by RGDG-DF are different by time and space. The image encryption scheme is an approximately “one-time pad”. 4) We propose an image encryption scheme based on RGDG-DF. The trajectory address sequence generated by RGDG-DF is used to create a P-box with the same size of plain image. A new permutation method is proposed to shuffle the positions of pixels totally using the P-box. The random sequences of RGDG-DF are used as keystreams in the diffusion steps. 5) This algorithm has a generalized key which only needs to be settled in the first time at both communication sides. No secret key needs to be exchanged during the encryption process. Experimental results show that the random sequences pass the NIST statistical test[30] with a high ratio and the new encryption scheme has feasibility and superiority.
The rest of the paper is organized as follows. In Section 2, we describe the generalized information domain, RGDG, and the proposed RGDG-DF. In Section 3, we describe the scheme of image encryption and decryption. The experimental results and security analysis are given in Section 4. Finally, Section 5 concludes the paper.
Generalized information domain (GID) is the space of all kinds of digital information stored in digital equipment or transferred over the Internet that can be expressed by binary code. With the development of the information technology and the Internet, GID is so large that it can be seen as an infinite space to some extent. In this paper, we denote the generalized information file as GIF which refers to the file in GID. Because of the diversity of users in cultural background, career, interests, habits and so on, the user’s choice of GIF from GID can be seen as random behavior and an entropy source that is easy to get without any other facility. Zhang et al.[29] proposed a random number generator based on discrete trajectory transform in the generalized information domain (RGDG). In RGDG, they first reconstruct the GIF and user input using shift operation with restriction condition to get the data stream which has good statistical properties and appropriate length denoted by background (BG). Then, a discrete trajectory extraction (DTE) method is proposed to extract the random number from BG. A system random source called initial value IV = {t,r,u} where t is system time, r is a system random number, and u is the user’s personalized input that is introduced. IV is used to calculate the extraction position and the extracted data is used in updating the IV in a feedback mechanism. Experimental results showed that RGDG had superior randomness and passed the NIST statistical test with a high ratio. However, we found that RGDG spends most of the time on calculating extraction positions. To speed up RGDG and preserve its good property at the same time, we propose an accelerated scheme based on drift factor (DF) in this paper, called RGDG-DF. DF is 32-bit vector used in the process of calculating extraction positions in Section 2.3.
According to Ref. [29], GIFs usually have bad statistics properties such as low information entropy, high correlation coefficient, etc. To generate random number sequences, we also reconstruct GIF first to get a sequence with an appropriate length and good statistics properties which is called BG.
The reconstruction process includes n rounds. We note GIF as RB0 (reconstruction block) and the result of the ith round of reconstruction as 


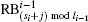
In Eq. (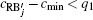
BG cannot be used as random sequence directly because it has some regular pattern, not random. Therefore, an extraction method is used to generate random number sequences. The process of generating random number sequences SK and trajectory sequence PK from BG can be presented as (SK,PK) = f (BG,IV,D), where f is the extraction function. In each extraction operation, four bits of data are extracted from BG and added into the final random sequence based on some restriction condition. We introduced another counter vector denoted by 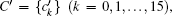

The extraction process is given as follows.


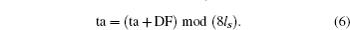

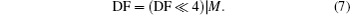
Repeat Steps 3–9 until we get sequence SK of requested length. Another sequence SK′ can be generated similarly. In addition, we record the ta sequence denoted by PK which will be used in the permutation part of the image encryption process.
In RGDG, analysis results show that the computation of Eq. (
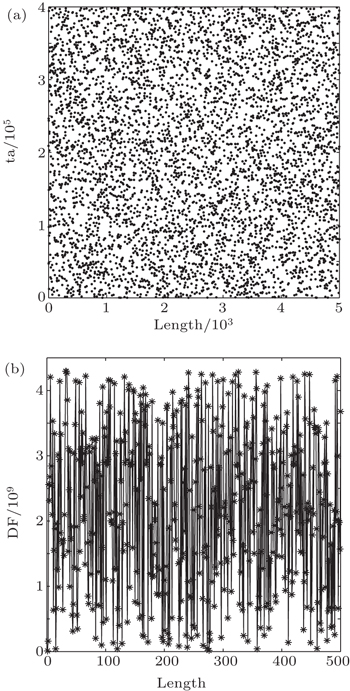
 | Fig. 1. (a) Distribution of ta sequence on BG (500000 bits), (b) changing process of DF. |
RGDG-DF has key K = {GIF, (S,L),D}, parameters q1 and q2. The suggested value ranges of parameters are summarized as below.
The encryption algorithm is based on the permutation–diffusion architecture. The random sequence PK is used to generate a P-box then shuffle the plain image while SK′ and SK are used to diffuse the shuffled image. Some papers[16,28] have shown that one round permutation–diffusion is not secure enough especially against chosen plain text attack. Therefore, we add a pre-diffusion to confuse the plain image. Moreover, a new shuffle method is proposed in the permutation process. When encrypting any two images the IVs are different in time and space because ST is different in time and SI is different in space. In practical situations, different IVs usually result in different keystreams. Thus, this encryption algorithm is an approximately one-time pad.
Without loss of generality, we assume the plain image is a 256 gray-scale image of size M × N which can be seen as a one-dimensional vector P = (p1,p2, …, pM×N), where pi denotes the gray level of the image pixel in the row floor (i/N) column mod (i,N). The algorithm can be described as below.
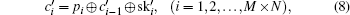
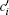
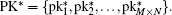
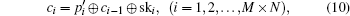
The decryption process is similar to the encryption process and is the inverse of the encryption process.
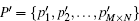
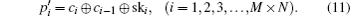
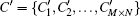
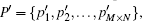
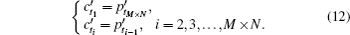
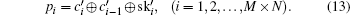
In our scheme, we propose a new shuffle method shown in Eq. (
We choose 10 groups of different keys and parameters as shown in Tables
| Table 1. Ten groups of keys and parameters for the NIST tests. Groups 1–5. . |
| Table 2. Ten groups of keys and parameters for the NIST tests. Groups 6–10. . |
| Table 3. Results of the NIST statistical test (at the 1% level). . |
From Tables
Key space size is the total number of different keys which can be used in the encryption. A good encryption algorithm should be sensitive to the secret keys, and the key space should be large enough to make brute-force attack impossible.
In our algorithm, GIF together with parameters (S,L), D denoted by K = {GIF, (S,L),D} can be seen as generalized key compared with traditional symmetric cryptography. This generalized key is different from the traditional key of a modern cryptography system such as DES, AES in three ways: (i) the length or size of K is not fixed, (ii) the key space is infinite, (iii) K can be stored in the facility of both sides of the communication and does not need to be transferred in a long time. GIF can be any digital file from the GID so its space is infinite theoretically. As mentioned before, we suggest that the size of GIF should range from 0.5 KB to 10 MB. Suppose the size of GIF is 1KB, then the space of GIF is 21024×8 = 28192. (S,L) = {(si,li)}, (i = 1,2,…,n), where si and li are 32-bits integer and n ∈ [3,7]. Suppose n = 3, then the space of (S,L) is 232×2×3 = 2192. D = (d0,d1,…,dm), (i = 0,1, …,m), where di is 32-bits long. If m = 4, then the space of D is 232×5 = 2160. Thus, the key space of our algorithm is at least 28192+192+160 = 28544 which is so huge that it can prevent brute-force attack.
For experimental analysis, IV remains unchanged in Subsection 4.3–4.5 and the corresponding AI is given in Table
| Table 4. Key K0 and parameters. . |
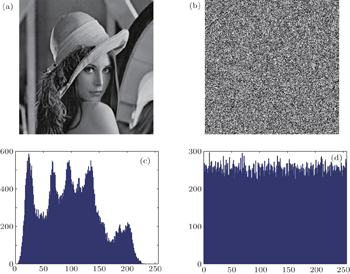
Image histogram is a very important feature in image analysis. Figures
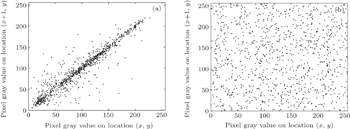
Correlation between pixels is an important intrinsic feature of an image. To resist statistical analysis, a good encryption algorithm should remove the high correlation of the plain image. We select all the pairs of two-adjacent pixels in vertical, horizontal, and diagonal directions from the plain image and the cipher image, and calculate the coefficient by
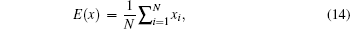
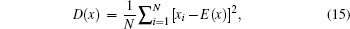
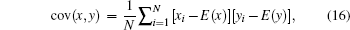

We test the correlation coefficients of adjacent pixels in the plain image “Lenna” and its cipher image and the result is listed in Table
 | Fig. 2. (a) Plain image, (b) cipher image, (c) histogram of the plain image, and (d) histogram of the cipher image. |
| Table 5. Correlation coefficients of two adjacent pixels in the plain image and cipher image. . |
 | Fig. 3. Correlations of two horizontally adjacent pixels: (a) correlation of the plain image and (b) correlation of the cipher image. |
The information entropy is an important feature of the randomness and the information entropy H(s) of a message source s can be calculated as
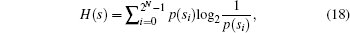
| Table 6. Entropy value for the cipher images. . |
| Table 7. Entropy value for cipher images of “Lenna”. . |
In order to measure the different ranges between two images, we use NPCR (number of pixels change range) and UACI (unified average changing intensity),
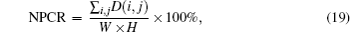
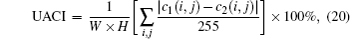
Key sensitivity is an essential feature for any good cryptosystem which guarantees the security of the cryptosystem against the brute-force attack to some extent. In the proposed algorithm, the generalized key K = {GIF, (S,L),D} is composed of several parts so we run several tests for each part of the key K separately. We randomly change one bit of GIF 1000 times to get 1000 slightly different GIFs and keep (S,L), D unchanged. We encrypt image “Lenna” using K0 and these 1000 keys and calculate the average NPCR and UACI of the cipher images using Eqs. (
| Table 8. NPCR and UACI between cipher images with key K0 and slightly different keys. . |
In order to resist differential attack, a tiny change in the plain image should cause a substantial change in the cipher image. Given a 256 gray-scale plain image P of size 256×256 and get a P′ which only has a single pixel difference in a random position (i, j), where i, j = 0,1, …,255,
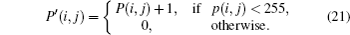
Encrypting P and P′ obtains the cipher images C and C′, then we calculate NPCR and UACI using Eqs. (
| Table 9. NPCR and UACI between cipher images with slightly different plain images. . |
We have used Microsoft Visual Studio 2010 to run RGDG,[29] RGDG-DF, encryption and decryption programs in a personal computer with an Intel Core i3 CPU 2.53 GHz, 2 GB memory and 250 GB hard-disk capacity, and the operation system is Microsoft Windows 7. The average speed of RGDG-DF is 8.29 M/s and the average speed of RGDG is 5.78 M/s. The average time of encryption/decryption on 256 gray-scale images of size 512 × 512 is 150 ms. Considering the speed of the Internet transmission, our algorithm can well satisfy the practical situation.
Compared with that in Ref. [29], we add a random value SI in the initial value IV. It can be deduced that when encrypting any two images, IVs must be different. ST is system time generated by computer system so when encrypting images at different times the STs are different. SI is system unique identifier such as hard disk number, mainboard number, etc. When encrypting the two images at the same time then they must be at different machines so that SIs are different. It is easy to notice that Eq. (
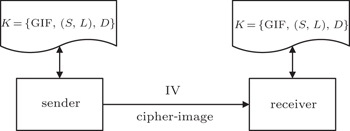
Key management includes key storage, key backup/recovery, and key period. In our scheme, the key K = {GIF, (S,L),D} can be seen as a generalized key compared with traditional symmetric cryptography. The process of the communication in practical usage is shown in Fig.
 | Fig. 4. Communication of the sender and receiver. |
In this paper, we propose a novel image encryption method based on random sequence generated from generalized information domain and permutation–diffusion architecture is proposed. This algorithm takes user’s random choice of the GIF as the entropy source and generates a random sequence by reconstruction from GIF and discrete trajectory extraction from the data stream. A new drift factor is introduced to accelerate and enhance the random generator. The trajectory address sequence is used to generate a P-box and then shuffle the plain image conpletely using a new permutation method and the random sequence is used as the keystream. A unique IV composed of ST, SI, and UI is introduced to make the encryption method an approximately one-time pad. Thus, the proposed scheme shows good resistance to the known plain text and the chosen plain text attacks. Experimental results show that the random sequences can pass the NIST statistical test with a high ratio. The key space is large enough to resist brute-force attacks. Statistical analysis shows that the cipher image of the scheme has high information entropy and low correlation coefficients so that it can resist statistical attack. The scheme has high key sensitivity and plain text sensitivity to anti differential attack. Moreover, the scheme has a high encryption speed. This algorithm has great advantages in practical use especially in some special areas which require high security such as military systems.