







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Universal relation for transport in non-sparse complex networks*
[Wang Yana) , Yang Xiao-Rongb)  ]
]
]
|
|


†Corresponding author. E-mail: xzdxyr@sina.com
*Project supported by the National Natural Science Foundation of China (Grant Nos. 11305268 and 11465017).
Transport properties of a complex network can be reflected by the two-point resistance between any pair of two nodes. We systematically investigate a variety of typical complex networks encountered in nature and technology, in which we assume each link has unit resistance, and we find for non-sparse network connections a universal relation exists that the two-point resistance is equal to the sum of the inverse degree of two nodes up to a constant. We interpret our observations by the localization property of the network’s Laplacian eigenvectors. The findings in this work can possibly be applied to probe transport properties of general non-sparse complex networks.
Understanding transport processes in disordered media is of great relevance to many scientific fields, ranging from condensed matter physics to petroleum engineering.[1– 3] It is a common way to model the disordered media as complex networks and the transport processes in them can in many cases be modeled as currents flow in random resistor networks. Network structure has a paramount impact on the transport processes, and such impact reflects the transport property of the network, which may be quantitatively represented by the statistics of the two-point resistance Ri j, or equivalently the two-point conductance Gi j, between any pair of node i and node j in the network. An elegant result[4] was obtained that for a scale-free (SF) network[5] whose degree distribution is 

 |
holds for all types of networks considered, as long as they are not too sparsely connected. Equation (1) is essentially equivalent to the Gi j scaling found in Ref. [4] for SF and ER networks, where a physical “ transport backbone” picture was provided to interpret it. Meanwhile, here we take advantage of the localization property of Laplacian eigenvectors to show why equation (1) holds for networks considered in this work, and we expect the localization of Laplacian eigenvectors is present for general non-sparse networks, hence we conjecture that equation (1) is actually a universal relation. This finding paves the way to infer transport properties of general non-sparse complex networks only from the degree distribution. In addition, equation (1) can be used to estimate two-point resistance when the network structural information can only be partially or locally known.
We consider a complex network as a resistor network represented by the adjacent matrix A, with Aij = 0 if node i and node j are not connected or Aij = 1 if node i and node j are connected by a resistor of unit resistance. The voltage of node i is denoted by Vi. To calculate the two-point resistance, we inject a constant current I to node i and through node j the current flows out of the resistor network, then, the two-point resistance with respect to nodes i and j is Rij = (Vi − Vj)/I. The net current for any node m can be written as Im = I(δ mi − δ mj). The Kirchhoff’ s law states that

where L is the Laplacian matrix of the network with its component Lij = kiδ ij − Aij, and V and I are the vector forms of voltage and net current, respectively. We numerically solve Vi and Vj to obtain Ri j, and we estimate Ri j by

Results for various networks below show that for dense network connections the ratio 

For simplicity, SF networks considered in this work are constructed according to the preferential attachment rule, [5] and we investigate how effective the estimation of Ri j by 

Exponential (EXP) networks refer to networks with exponential degree distribution, which is commonly observed in rock pore networks[7] and other networks such as North America power grid.[8] To generate this type of network, we use the method in Ref. [5] by growing the network with each newly introduced node with kmin links connecting to existing nodes with equal probability. In Fig. 1 we plot 
 | Fig. 1. The average value of   |
To generate small-world (SW) networks, [9] we start from a regular ring lattice with each node connecting to its 2knn nearest neighbors, and we rewire each link with a probability pr while keeping the total number of links fixed. As can be seen in Fig. 2, as the network is getting more densely connected by increasing knn and pr, the estimation of Ri j by 
 | Fig. 2. The average value of 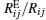  |
The clustered networks are generated as in Ref. [10]. Nodes in the same cluster are randomly connected with probability pin, while nodes in different clusters are connected with probability pout. Without the loss of generality, we fix pin = 0.8. We also let the number of clusters in the network be Nc = 10. Again, we observe in Fig. 3 better estimations of Ri j by 


 | Fig. 3. The average value of   |
We have shown the validity of Eq. (1) for various types of random networks as long as they are non-sparsely connected. However, the precise definition of “ non-sparseness” seems elusive, partly because of the fact that estimating Ri j by 

Nonetheless, we argue non-sparse random connections are expected to be encountered in random networks with a fairly large size and without a local tree structure. (In fact, a local tree structure is routinely used as a feature of “ sparse” networks.) To further address this point, we define the coefficient of variation cv for the ratio 
 |
Intuitively, if a network is sparsely connected, then σ E is large, and so is cv. As the network becomes more densely connected, σ E is diminishing, resulting in an also vanishing cv. In Fig. 4 we plot for SF networks how cv is changed as N and kmin are increased. (Though it might be problematic to refer to a network with N < 100 as an SF network, we generate networks with different N from the same preferential attachment rule to see the effect of network size N on the estimation of Ri j by 

 | Fig. 4. The coefficient of variation cv for  |
Qualitatively similar results can also be found for other types of networks, and it is interesting to investigate in more detail how the non-sparseness condition can be achieved in a network in the future, however, this is beyond the scope of the present paper. Despite the term “ non-sparse” being mathematically not rigorously defined, we use it in a practically unambiguous way to refer to typical complex networks encountered in nature and technology which contain thousands of nodes that are usually connected to more than one neighbor.
We will show in the following that the localization of Laplacian eigenvectors can be used to explain Eq. (1) for all types of networks considered in this work, and possibly for other types of non-sparse complex random networks. Our analysis rests heavily on the theory developed in Ref. [11], where the exact value of Ri j is obtained using eigenvalues and eigenvectors of the Laplacian matrix L as
 |
where Ui j is the i-th row j-th column element of a matrix U, whose m-th column is the m-th eigenvector, um, of L, and λ m is the associated m-th eigenvalue in ascending order with 0 = λ 1; Ψ i, Ψ j, and ψ ij are defined to be the three terms on the right-hand side of Eq. (3), respectively. Equation (3) is an exact result that applies to any network, and it has been used to calculate Ri j for regular lattices.[11] This work has aroused much interest, and more sophisticated situations have recently been considered.[12, 13] However, we use the method to numerically compute Ri j for non-sparse random networks and we find actually Ψ i and Ψ j suffice to effectively estimate Ri j because typically we have
 |
for all kinds of networks considered in this work.
A systematical investigation over typical distributions of | ψ ij| /(Ψ i + Ψ j) for various types of networks is conducted, and results are shown in Fig. 5 with a fixed N = 1000. The SF networks with kmin = 3 and kmin = 10; ER networks with p = 0.006 and p = 0.1; EXP networks with kmin = 3 and kmin = 10; SW networks with pr = 0.06 and pr = 0.6 (knn = 3); SW networks with pr = 0.06 and pr = 0.6 (knn = 5); clustered networks with pout = 0.001 and pout = 0.05 are shown in Figs. 5(a)– 5(f), respectively. For each type of network, the corresponding typical distribution is not necessarily similar to those of other types of networks, and the specific distribution itself, though worth studying, is not our main interest at present. Rather, we focus on the effect of increasing random connections in networks on the distributions. In all the cases, as the random connections among nodes in networks are denser, distributions shift leftward, i.e., | ψ ij| is more likely to be negligible as compared with Ψ i + Ψ j, validating the inequality (4). This fact implies that for non-sparse random networks we can rewrite Eq. (3) as
 |
 | Fig. 5. Typical distributions of | ψ ij| /(Ψ i + Ψ j) are plotted for various types of networks with different parameters and a fixed N = 1000. (a) SF networks with kmin = 3 and kmin = 10; (b) ER networks with p = 0.006 and p = 0.1; (c) EXP networks with kmin = 3 and kmin = 10; (d) SW networks with pr = 0.06 and pr = 0.6 (knn = 3); (e) SW networks with pr = 0.06 and pr = 0.6 (knn = 5); (f) clustered networks with pout = 0.001 and pout = 0.05. |
Moreover, our numerical results further reveal that Ψ i actually displays a strong linear dependence on 
 |
inserting which into Eq. (5), one finds Eq. (1). To validate the linear dependence of Ψ i on 1/ki, we show in Fig. 6 the results for SF, ER, and EXP networks, in which the linear dependence is most pronounced as kmin = 10 for SF networks, p = 0.1 for ER networks, and as kmin = 10 for EXP networks, respectively, with each case corresponding to the most densely connected network considered here. The results for SW and clustered networks are presented in Fig. 7; it is also straightforward to see that for SW networks, the linear dependence best manifests itself when knn = 5 and pr = 0.6, and for the clustered networks, when pout = 0.05. Again, in both cases, the corresponding networks have dense enough random connections.
 | Fig. 6. Ψ versus 1/k is plotted for SF, ER, and EXP networks (N = 1000). No relation between Ψ and 1/k is observed for extremely sparsely connected SF and EXP networks with kmin = 1. For the ER network with p = 0.006 the linear dependence is approximate, while an evident linear dependence is observed as kmin = 10 for SF and EXP networks, and as p = 0.1 for ER networks, corresponding to more densely connected networks in all the cases. |
 | Fig. 7. Ψ versus 1/k is plotted for SW and clustered networks (N = 1000). For SW networks, both with knn = 3 and knn = 5, the linear dependence of Ψ on 1/k does not manifest itself for a low rewiring probability pr = 0.06, but it does appear for a high rewiring probability pr = 0.6, and the case in which knn = 5 and pr = 0.6 shows the best linear dependence of Ψ on 1/k. For clustered networks, the linear dependence is also more evident as the inter-cluster connection probability pout is increased. |
With the above numerical results, we can conclude that for non-sparse random networks, equation (1) is a natural outcome of Eq. (3) when the inequality (4) and the linear dependence (6) are taken into account. However, why do the latter two hold? We argue that this can be understood via the localization property of Laplacian eigenvectors. To proceed, we let the degrees of all nodes in a network be sorted in ascending order such that k1 ≤ · · · ≤ kN. By localization, we mean the dominant part of components of the Laplacian eigenvector um, which is associated with the m-th eigenvalue λ m, lies on the nodes that have degrees close to km.[14– 17] We plot in Fig. 8 how the components of Laplacian eigenvectors are distributed on nodes. Nodes in a network are divided into groups based on their degrees; nodes with the same degree belong to the same group. For example, nodes in group i all have the same degree Ki. If a network has Nd groups, then we can denote the distinct degree sequence of such groups in ascending order as k1 < · · · < kNd; note that Nd is almost always less than N in a random network. We next compute the fraction, denoted fnm, of the m-th Laplacian eigenvector that is distributed in the group in which nodes have degree Kn

 | Fig. 8. Localization of Laplacian eigenvectors is shown for five types of networks. The network size is fixed to be N = 1000. We compute fnm for each Laplacian eigenvector um, whose corresponding eigenvalue is λ m. The diagonal pattern implies the localization of Laplacian eigenvectors. (a) SF, kmin = 1, (b) SF, kmin = 10, (c) ER, p = 0.006, (d) ER, p = 0.1, (e) EXP, kmin = 1, (f) EXP, kmin = 10, (g) SW, knn = 3, pr = 0.03, (h) SW, knn = 3, pr = 0.6, (i) SW, knn = 5, pr = 0.03, (j) SW, knn = 5, pr = 0.6, (k) clustered, knn = 3, pr = 0.001, (l) clustered, pout = 0.1. |
For each type of network considered, we find that as the random connections are increased, the localization of Laplacian eigenvectors becomes evident. However, different networks can show different fashions of localization, and we observe mainly two such fashions. Firstly, if there is a wide gap between km and km+ 1 or km− 1, and there is only one node with degree km, then fnm ≈ δ nm and the localization of Laplacian eigenvectors means
 |
This “ non-degenerate” case is typically encountered in SF and EXP networks when the hub nodes are concerned. Secondly, for the “ degenerate” case in which the spectral gap is narrow and there are many nodes having similar degrees, localization on one single node is unlikely, rather, components of um are localized on nodes with degrees close to km. That is to say, there is no single fnm that is close to 1, however, there exist n′ groups such that ∑ n′ fn′ m ≈ 1 with kn′ ≈ km. Then, one can roughly write that
 |
where χ [a, b](x) denotes the indicator function, which equals 1 if a ≤ x ≤ b and equals 0 otherwise, and Δ km is some threshold that represents the size of the window, in which we consider the degree is close enough to km. This is the typical case observed for ER, SW, and clustered networks. We can see that for ER networks, the localization manifests itself on nodes with similar degrees as p is increased. Similarly, for SW networks, as knn and pr are increased, more random connections are introduced, and the localization emerges on nodes with similar degrees. Note the difference between Figs. 8(g) and 8(j). For clustered networks considered in this work with pout ≈ 0, it is structurally quite distinct that there are Nc = 10 clusters, hence we have λ 1 = 0 and λ 2 ≤ · · · ≤ λ Nc≪ 1. The eigenvectors associated with the smallest Nc eigenvalues are not localized at all, and these small λ , which are characteristics of clustered networks with quite sparse inter-cluster connections, greatly influence the value of Ψ [see Eq. (3)], leading to the failure of Eq. (1). As pout is increased, the gap between these Nc − 1 smallest nonzero λ and 0 is also increased, and their influence on Ψ becomes negligible. In addition, for λ > λ Nc, the localization becomes more distinct as pout is increased, thus an overall reasonably good localization pattern is observed for clustered networks. Therefore we conclude that the localization of Laplacian eigenvectors becomes evident as the random connections are dense for all types of networks.
We also note that if we let Δ km = 0 in Eq. (8) and there is only one node with degree km, then equation (7) can be recovered by noticing 
Now, we present a qualitative analysis to show why equation (1) holds. Starting from Eq. (8) and considering networks in which random connections are dense enough, as a zeroth order approximation, we uniformly distribute components of Laplacian eigenvectors on nodes whose degrees are close to km, so
 |
where Nm is the number of nodes whose degrees are close to km, and it can be computed as

Inserting Eq. (9) into the definition of Ψ i, we have
 |
Note that the nonzero terms on the right-hand side of Eq. (10) only originate from the case that the degree of node i is close to that of node m. However, if ki ≈ km, then vice versa, say, km must be in the neighborhood of ki, and we intuitively have
 |
which implies
 |
In addition, we further make use of the approximation that for densely connected networks
 |
This approximation is verified by our numerical results in Fig. 8 when the localization of Laplacian eigenvectors is present, and it was also noticed previously for SF and ER networks.[15] Inserting Eqs. (11)– (13) into Eq. (10), we obtain the linear dependence (6), while for ψ ij, if it is non-negligible compared to Ψ i + Ψ j, then both node i and node j should have similar degrees. For a given ki, the probability that ψ ij cannot be omitted is typically as low as 
Despite the simplifications made in our qualitative theoretical interpretation, we manage to find out a plausible reason why the inequality (4) and the linear dependence (6) hold by taking into account the localization property of Laplacian eigenvectors Eq. (8), based on which equation (1) can be established. In addition, we do not require any specific topology other than the non-sparseness of networks in our interpretation, therefore we expect that equation (1) holds for general non-sparse complex random networks.
In this work, we have systematically investigated the two-point resistance Ri j of various types of complex networks that are frequently encountered in nature and technology, including scale-free, Erdő s– Ré nyi, exponential, small-world, and clustered networks, and we find a seemingly universal relation [Eq. (1)], which states that as long as a complex random network is not too sparsely connected, Ri j can be effectively estimated by the degrees of node i and node j. Our finding is consistent with that obtained in Ref. [4] where scale-free and Erdő s– Ré nyi random networks were considered. With the theory established in Ref. [11], we also provide an explanation to Eq. (1) by arguing that the underlying mechanism is the localization of Laplacian eigenvectors.[15] In particular, our analysis is based on the fact that components of the m-th Laplacian eigenvector um are typically localized on nodes with degree close to km, as observed in all types of networks that are not sparsely connected. (However, a more rigorous theory to explain the finding in this work is still awaited.)
One implication of our work is that provided just a few number of Ri j can be measured directly from experiments and only local connectivity information is available, we can compare the estimated values of two-point resistance based on Eq. (1) and the experimental results. If they are consistent with each other, then the network is possibly non-sparse and the constant C can be fixed, so the two-point resistance of any other two nodes in the network might be further estimated accordingly, as long as their local structural information is available. Also, if the degree of node i is known, and the two-point resistance Ri j can be measured, then the degree of node j can be effectively estimated. Furthermore, with Eq. (1), the two-point resistance distribution Φ (Rij) is naturally obtained as Φ (Rij) = ∬ P(ki)P(kj)δ (R/C − 1/ki − 1/kj) dkidkj. This can be essentially applied to investigate the transport properties in terms of the statistics of Ri j for general non-sparse complex networks other than SF and ER networks as in Ref. [4].
We consider in this work for simplicity that each link has unit resistance, and there is only one pair of source and sink nodes. However, realistic networks are often weighted and there are multiple sources and sinks.[18– 21] Of particular interest and relevance to water science and petroleum engineering is the case that involves the network model of rock’ s pore space, which is embedded in three-dimensional Euclidean space with the link’ s hydraulic resistance dependent upon its length and cross-sectional area, and the network is typically subject to constant pressure or current condition at two ends. It is our future work to study how the findings here can be used to get insights for transport processes in realistic complex pore networks where the network structure can qualitatively influence the transport process.[22, 23]
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
|
| 9 |
|
| 10 |
|
| 11 |
|
| 12 |
|
| 13 |
|
| 14 |
|
| 15 |
|
| 16 |
|
| 17 |
|
| 18 |
|
| 19 |
|
| 20 |
|
| 21 |
|
| 22 |
|
| 23 |
|