
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Deductive way of reasoning about the internet AS level topology*
[Szabó Dávida)  , Kőrösi Attila
, Kőrösi Attilaa), c) , Bíró Józsefa), b) , Gulyás Andrása), c) ]
, Kőrösi Attila|
|


†Corresponding author. E-mail: szabod@tmit.bme.hu
*Project supported by Ericsson and partially supported by the Hungarian Scientific Research Fund (Grant No. OTKA 108947).
Our current understanding about the AS level topology of the Internet is based on measurements and inductive-type models which set up rules describing the behavior (node and edge dynamics) of the individual ASes and generalize the consequences of these individual actions for the complete AS ecosystem using induction. In this paper we suggest a third, deductive approach in which we have premises for the whole AS system and the consequences of these premises are determined through deductive reasoning. We show that such a deductive approach can give complementary insights into the topological properties of the AS graph. While inductive models can mostly reflect high level statistics (e.g., degree distribution, clustering, diameter), deductive reasoning can identify omnipresent subgraphs and peering likelihood. We also propose a model, called YEAS, incorporating our deductive analytical findings that produces topologies contain both traditional and novel metrics for the AS level Internet.
One simply cannot overestimate the value of knowing more about the topology of the Internet. The last decades have supplied us with thousands of stories where topology-related information about the Internet was directly transformed into more efficient architectures and services, or more appropriate business decisions. The most specific example is clearly content delivery networks (CDN), [1] where global topological peculiarities are highly exploited e.g., in surrogate and cache placement strategies or request routing mechanisms[1] but CDN is just a narrow segment of the whole spectrum. The placement of data centers, [2] peer-to-peer networks, [3, 4] traffic engineering, [5] business based AS peering strategies, [6] just to mention a few, can clearly benefit from Internet topology related knowledge. The investigation of the AS topology is also a popular topic[7– 13] in the network science community, which consolidates researchers from diverse or multidisciplinary research areas. One reason behind this popularity is that compared to other complex networks, active and passive measurements can be executed on the Internet topology, thus we can create Internet “ screenshots” easily. Despite the diversity of the contributing research population about the Internet’ s autonomous systems (AS) level topology the way the results are produced seems to be centered around two mainstream approaches.
One way of getting usable information about the AS topology is simply measuring it. Today we have historical and contemporary measurement data collected continuously and made publicly available according to various approaches (e.g., using BGP info, [14, 15] traceroute measurements, [16] IXP anatomy[17]). Meanwhile the data stemming from these measurements are the exclusive source of direct information about the AS topology and thus can be treated as the ground truth we can keep ourselves to, the way these measurement systems work is continuously reported to be imperfect and far from optimal.[17] Additionally the collected data reveals only the current state of the network and cannot give usable predictions and clear characterization of the topology forming processes lying in the background.
The other approach is what we can categorize as the “ inductive models” . Here inductive means that we set up models making premises for the individual network nodes and generalize the results. We can say this is the de facto way of getting information about complex networks and basically all known Internet models belong to this category starting from probabilistic random graphs, [18] general complex network models e.g., [19] metric space models e.g., [20] fractal models, [21] random walk models, [18] optimization models[22] but simulation based approaches[23, 24] are counted here too. Although the corresponding volume of the literature is considerable still we can identify the following points in almost all cases.
(I) Define node dynamics This is usually a set of rules regarding how the set of nodes residing in the network varies over time. In the simplest case the set of nodes can be fixed a priori[18] but growth models e.g., [19] where the number of nodes increases over time seems to capture a fundamental aspect of the AS topology.
(II) Define edge dynamics This is again a rule set controlling how the edges are created between the nodes in the network. The set of rules here can be constructed in a black box fashion[18] where we just want to mimic some high level edge statistics (degree distribution, diameter, clustering, etc.) of the AS network, but also can be inspired by processes[19, 22] assumed to take place on networks.
(III) Analyse and compare with measurement data This final and most crucial step where the outcomes of the model are computed, simulated or analytically derived and verified against the available measurement data.
While the above three-step process resulted in a high variety, often precise (as far as the power of measurement data can verify) and usable Internet models, the inductive approach suffers basically from the inability to prove that the processes these models are defined upon, are actually there on the real AS network. For example one cannot really think that preferential attachment in its pure form (where an AS chooses its peers according to their exact nodal degree) is happening in the AS ecosystem. This inability makes the inductive models and their predictions somewhat ambiguous.
In other words the knowledge we can gain through measurements and inductive models do not really focus on deeper understanding of the networks, as incentives of nodes are unnoticed, and the self-organizing nature of the network formation process remains unrevealed. To cover the self-organizing aspect of networks (and in particular the AS level Internet), in this paper we suggest a third approach which is in line with deductive reasoning thus we can call the produced models deductive models. In the deductive approach we make premises about the whole AS system and analytically prove their exact consequences regarding the topology of the AS level network. Thus the deductive approach will take the following steps.
(I) Define premises The first and most important part of the deductive approach is defining premises that should capture non-trivial aspects of the system yet permit analytical investigation. Regarding the premises we can make two mistakes: (i) We define wrong premises and in this case our results will be irrelevant. (ii) We define good but weak premises thus we draw valid but meaningless conclusions.
(II) Prove the theoretical consequences of the premises In this step we construct a model which is compliant with the defined premises and lends itself for analytical investigations. The consequences for the AS topology then should come in the form of theorems with proofs.
(III) Compare the results with measurement data Mainly serves double-checking purposes if the premises and the analysis are done right.
The above three-step list highlights both the strengths and the weaknesses of the deductive approach. If the premises and the analysis are correct then we gain absolute knowledge about the AS system which provides legitimate predictions until the premises still hold. On the negative side if the premises are wrong, weak or cannot be turned into an analytically tractable model, then we can end up with irrelevant, meaningless or very high level conclusions that cannot be translated into useful messages for Internet practitioners. Finally, we note that we find the deductive approach as somewhat complementary and not supplementary of the inductive one as the two approaches try to tackle the AS network from completely different angles and, as we will see, can provide totally different insights. By understanding the inherent self-organization we have the possibility to predict trends and changes in a complex network that makes us capable to act proactively.
In the rest of this paper we attempt to find a usable set of premises for the Internet AS level topology (Section 2) and construct a model through which the claims stemming from our premises can be formalized and analytically verified (Section 3). In Section 4 we present a topology generator, based on our deductive results, which is able to produce networks that mimic a wide range of features of the AS level Internet. In Section 5 we conclude by describing the possibilities for future work.
In the followings we systematically go through the above three-step process of deductive reasoning regarding the Internet AS topology.
Over the last four decades the Internet has evolved from a carefully engineered computer network, connecting universities and research institutes in the US, into a complex ecosystem on top of an overwhelming variety of stakeholders all over the world. The network science community emphasizes mostly the resemblance of the AS network to many real world self-organizing networks, which is clearly the case but we argue that this network also has a second face as it apparently exhibits topological peculiarities stemming from technological underpinnings (e.g., the used networking technologies and protocol stacks). It seems that the underlying interdomain routing protocol of the Internet provides a good starting point for finding an analytically tractable set of premises for our deductive reasoning while providing non-trivial insights into the lineament of the AS network’ s technological face.
The interdomain routing policies of all the ASes are expressed through the well defined framework of the border gateway protocol (BGP).[25, 26] The main responsibility of BGP is to distribute the available forwarding paths between ASes and let them select their preferred paths according to their own special interests. Table 1 recalls a simplified version of the usual steps of the route selection process in BGP from Refs. [27] and [28]. Here we highlight the vital valley-free criteria as rule No. 0, since BGP path selection works over valley-free paths. In this work we pick the first two steps (valley-free policy and local preference) of this process to be our premises as these rules can capture non-trivial aspects of interdomain routing yet permitting analytical tractability.
| Table 1. The simplified BGP best path selection process. |
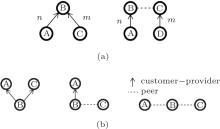
Premise 1 (valley-free routing policy) In the AS ecosystem the business relationships between ASes can be quite diverse, still we can classify most AS– AS links into basically two major groups:[29] in a customer– provider relationship the customer AS pays the provider for forwarding its traffic, while in a peering relationship neighboring ASes voluntarily exchange traffic with each other in a settlement-free manner.[35] The valley-free policy manifests the simple economic principle that the flow of traffic must coincide with the flow of cash. In very short the policy dictates that AS A can use a link to a neighboring AS B to forward the traffic if and only if either the incoming traffic is from a customer or B is a customer of A. Putting it differently valley-free compliant paths comprise arbitrary (may be zero) number of customer– provider links, zero or one peer link and again arbitrary provider-customer links strictly in this order (Fig. 1).
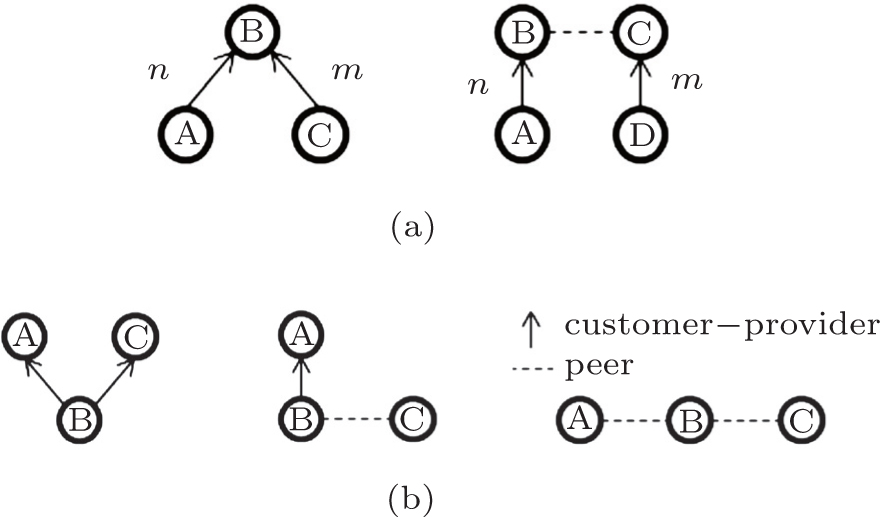 | Fig. 1. Illustration of valid (a) and invalid (b) valley-free path types. A valid path contains n customer– provider, at most 1 peer and m provider-customer link strictly in this order, where n, m ∈ ℕ . All the other types are invalid paths. |
Premise 2 (local preference policy) The local preference policy is applied on top of valley-free routes meaning that an AS can pick one from the available valley-free routes according to its local interest. Meanwhile these local interests can exhibit high variety the minimalistic rule that customer and peer paths are favored over provider paths, is contained in basically every local preference setting within the ASes. This is in line with the nature of these routes as customer and peer paths are completely free unlike provider paths in which the provider has to be compensated in some way for the carried transit traffic.
In what follows we propose a simple game-theoretical model built around Premises 1 and 2 through which their topological consequences can be analyzed.
Since the AS level topology is formed along the rational business decisions of the individual ASes, game theory is a natural modeling tool of choice. Therefore, in the followings we think about the ASes as rational but selfish players whose incentive is to communicate with each other using the policies defined in Premises 1 and 2. More formally, let 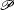

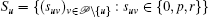
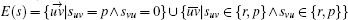
The goal of the players is to minimize their costs which for a given player u we define as
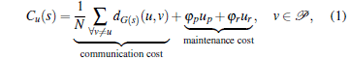 |
where
 |
represents the price of communication between u and v over G(s) in compliance with the policies defined in Premises 1 and 2, φ p and φ r are fix maintenance costs of the provider and peer edges and up and ur refer to the numbers of the p and r edges of u respectively. We note that the cost function in Eq. (1) is intentionally made as simple as possible for two reasons. First we want to concentrate purely on the consequences of our premises thus we avoid incorporating cost elements that can mask them. The second reason is simply analytical tractability. So basically the first sum in Eq. (1) represents the most simple way of capturing our premises and φ p and φ r are introduced for setting up a meaningful game (e.g., without attributing costs to the edges the game would end up in producing full graphs) but can be easily justified as inter AS links clearly have maintenance costs. Note that we regard provider– customer edges to be financed unilaterally by the customer.
The Nash equilibrium of the game is a state such that no player can further reduce her costs by altering her strategy unilaterally. Since we have a network game we will use the following more natural and slightly tailored equilibrium definition for our case.
Definition 1 (pairwise stable Nash equilibrium (PNE)[30]) We say G(s) constitutes a pairwise stable Nash equilibrium if (i) Nash equilibrium, (ii) ∀ uv ∈ E(G(s)) : Cu(s) ≤ Cu(s′ ) ⋀ Cv(s) ≤ Cv(s′ ), where s′ differs from s only in deleting uv edge from G(s), (iii) ∀ uv ∉ E(G(s)) : Cu(s) ≤ Cu(s′ ) ⋁ Cv(s) ≤ Cv(s′ ), where s′ differs from s only in adding uv edge to G(s) and (iv) contains no provider loops.[37]
Now we are interested in the equilibrium topologies of our game as these topologies will reflect the consequences of our premises. For our claims we need two more definitions.
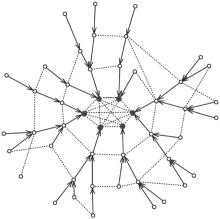
Definition 2 (Spider graph (Fig. 2)) A graph is a Spider graph if it consists of (i) a clique Kr (representing the tier-1 ASes) comprising peer edges only (ii) trees rooted at some subset of V(Kr) having customer– provider edges, such that the provider in the relationship is always closer to the root than the customer (iii) additional peer edges, such that 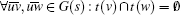
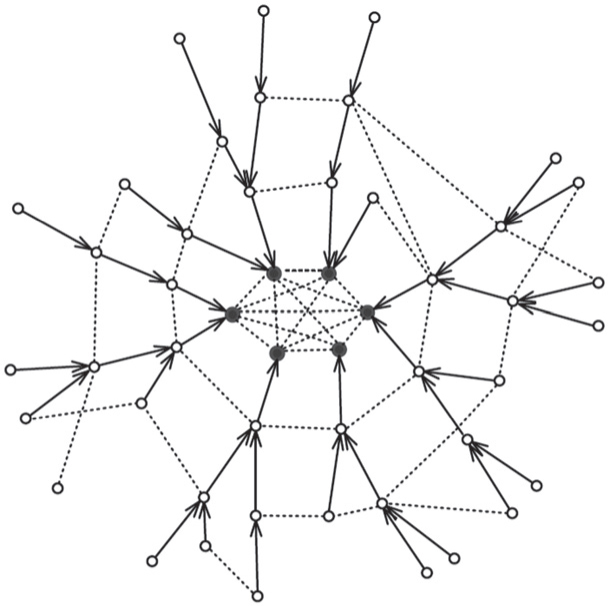 | Fig. 2. An example of the spider graph, the dashed and directed edges are the peer and customer– provider edges respectively and the black nodes are the ASes of the clique 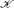 |
Definition 3 (clear-cut peer edge (CPE)) An 
Our first claim characterizes all meaningful states (i.e., where all the ASes can communicate with each other) of the above game (and thus the AS topology) by identifying an omnipresent subgraph.
Theorem 1 Every meaningful outcome of the game i.e., ∑ Cu ≠ ∞ contains the Spider graph as a spanning subgraph.
Proof The subgraph of the customer– provider edges is a spanning DAG, as provider loops are not allowed. For having ∑ Cu ≠ ∞ the sinks of this DAG has to be connected by peer edges in pairs. Hence the set of the sinks corresponds to the Kr clique of the Spider graph.
Obviously each AS has a directed customer– provider path to some ASes of Kr. Therefore, one spanning forest of the DAG and the Kr clique is a proper spanning Spider graph in the original graph.
Using Theorem 1 we can characterize the pairwise stable equilibria of the game.
Theorem 2 Every pairwise stable equilibrium of the game is the Spider graph.
Proof According to Theorem 1 any pairwise stable equilibrium contains the Spider graph as a spanning subgraph. Easily it contains a Kr clique in which ASes do not have customer– provider edges. If there are any extra customer– provider edges, then there must be an AS which has at least two customer– provider links. Since the additional customer– provider edge does not reduce the communication cost, but enlarges the maintenance cost, such outcome cannot be a Nash equilibrium.
If the subgraph of the customer– provider edges is a forest, then in it if exists two nodes v and w such that 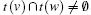
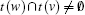
The following theorem gives a high-level insight into the placement of the peer edges.
Theorem 3 If G(s) constitutes a PNE then each peer edge is a CPE or part of Kr.
Proof We prove this indirectly. If there exists a peer edge out of Kr which is not CPE then either (i) φ r ≮ min {| t(u)| /N, | t(v)| /N} or (ii) ∃ w ∈ V(G(s)) : v ∈ t(w) ⋀
Finally our theorems lead to the following three corollaries.
Corollary 1 In a PNE a peer edge appears only if it is in Kr or its both endpoint ASes has sizable customer cones.
Corollary 2 For PNEs there exists an upper bound for the size of the customer cones of the ASes in Kr, or more formally 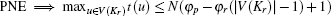
Proof The cost of a node u ∈ V(Kr) is φ r(| V(Kr)| − 1). However, if u leaves Kr and creates only one customer– provider edge to another node in Kr, its cost would change to [N − t(u)]/N + φ p. Hence in PNE
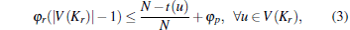 |
and thus
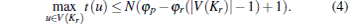 |
Corollary 3 In the case of PNE there exists an upper bound for the size of Kr independent from N, i.e.,

Proof According to Corollary 2,
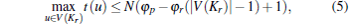 |
and obviously
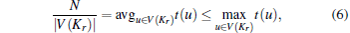 |
hence
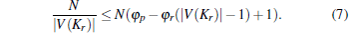 |
Dividing by N and rearranging the inequality we obtain
 |
implying
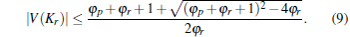 |
The above theorems deliver the following high-level sketch of the AS topology as a main intuitive message: (i) it is a Spider-like graph with a clique (of tier-1 ASes) in the center and trees routed in the nodes of the clique, (ii) the peer edges appear more likely between ASes having sizable customer cones, (iii) the size of the clique is constrained by the maintenance cost of peer and customer– provider relationships, and (iv) the largest customer cone size in the nodes of the clique is also driven by these maintenance costs.
For validating our analytical results we used the AS relationships dataset of May 2012, provided by CAIDA.[14] Although this dataset received some criticism over the last years, at this moment no other sources of data are available containing more accurate tracing of the peer and customer– provider edges at the AS level.
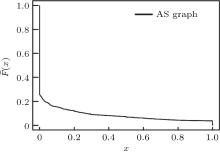
This dataset contains AS– AS relationships for 41203 ASes with 57158 peer and 83374 customer– provider edges, thus lets us build a labeled AS graph. Regarding Theorems 1 and 2 we investigated the existence of the Spider graph in two steps. First we followed the customer– provider relationships in a top– down manner proceeding from the top tier-1 clique and kept all the nodes we could reach, this way we get a 92.5% node coverage which properly validates that the AS graph meets the first two properties (clique inside and trees rooted on the nodes of the clique) of Spider graphs. Secondly, we examined how typical for an AS C with peering neighbors A and B that 
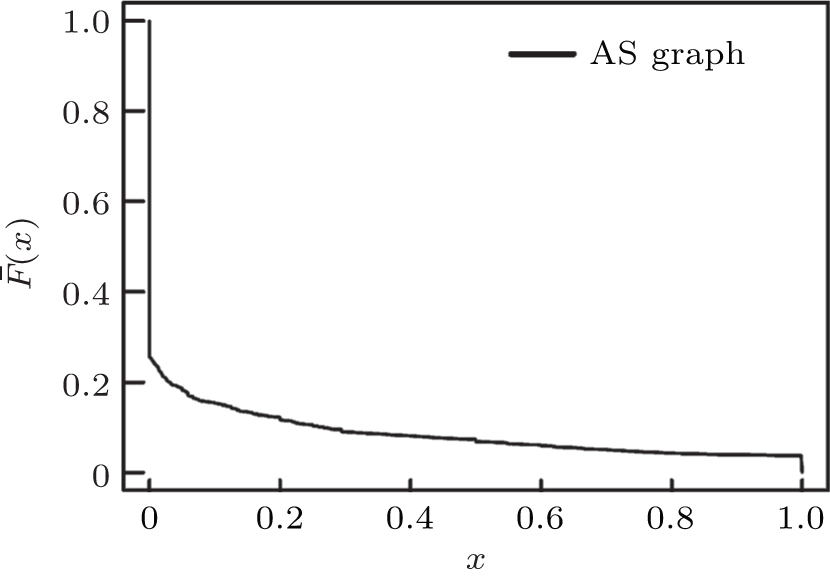 | Fig. 3. CCDF for coverage overlapping of peer edges of an AS defined as x = [t(A) ∩ t(B)]/[min{t(A), t(B)}]. |
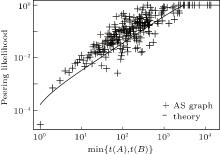
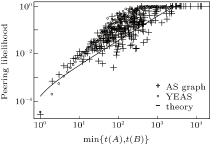
After that as a next step, we measured the peering likelihood between two ASes as a function of the minimum of their customer cone sizes. The AS graph dataset of Fig. 4 shows the empirical probability that two ASes with a given minimum customer cone size (min(t(A), t(B))) are in a peering relationship. The dataset supports that the peering likelihood is in high correlation with the customer cone sizes of the ASes in the peering relationship.
Finally, we present a short argument illustrating our deductive predictions on the maximum customer cone size and
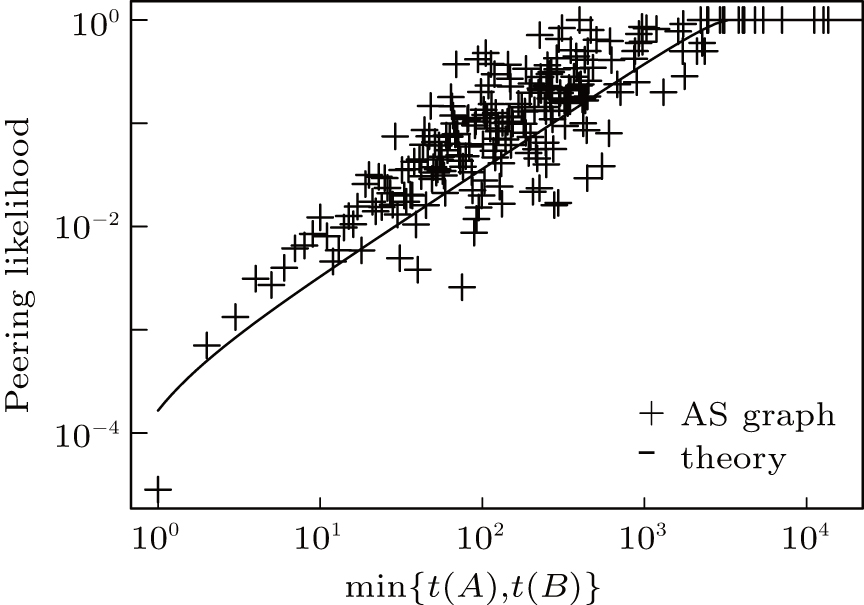 | Fig. 4. Peering likelihood between ASes as the function of their customer cone size. |
the max size of the tier-1 clique. For doing this we used historical AS datasets from CAIDA. Based on the number of customer– provider and peering relationships we have estimated
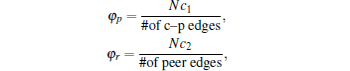
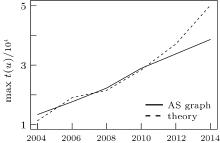
with c1 = 1.1 and c2 = 0.05. Using these values we have computed the results of our corresponding theorems and measured the max-conesize and tier-1 clique size as a function of time in the CAIDA datasets. Figure 5 shows that our rough estimation about the maximal customer cone size in the AS level Internet approximates the measured one based on CAIDA snapshots in a reasonable extent. Figure 6 shows the prediction of our model regarding the size of the tier-1 clique. Although our simple formulae forecast a more increasing trend, the order of magnitudes are quite the same in both cases.
As a discussion we first call the reader to notice the complementary nature of the deductive findings as opposed to the existing inductive models. While the existing inductive models concentrate on degree distribution, clustering, diameter, etc. the deductive reasoning give hints about spanning subgraphs, peering likelihood and constraints on the size of different parts of the network. We also recall that our deductive model is extremely simple and squeezes all maintenance cost related quantities into two constants (φ r, φ p). In the light of this simplicity it is remarkable that the model gives practically usable predictions regarding the size of the tier-1 clique and the maximal customer cone of an AS.
One may argue that the results coming out of our deductive analysis are somewhat weak and say little about the AS network. Such criticism may seem to be all right at first, but we find to be important and interesting in itself that the found topological peculiarities (summarized in Theorems 1, 2, 3 and Corollarys 1, 2, 3) are direct consequences of the used BGP policies and thus will be present on the AS topology as far as these policies are used. We believe that showing this causality contributes to our very limited amount of information about the Internet AS level topology. Finally we note that more powerful premises can lead to more precise deductive topology characterization in future work.
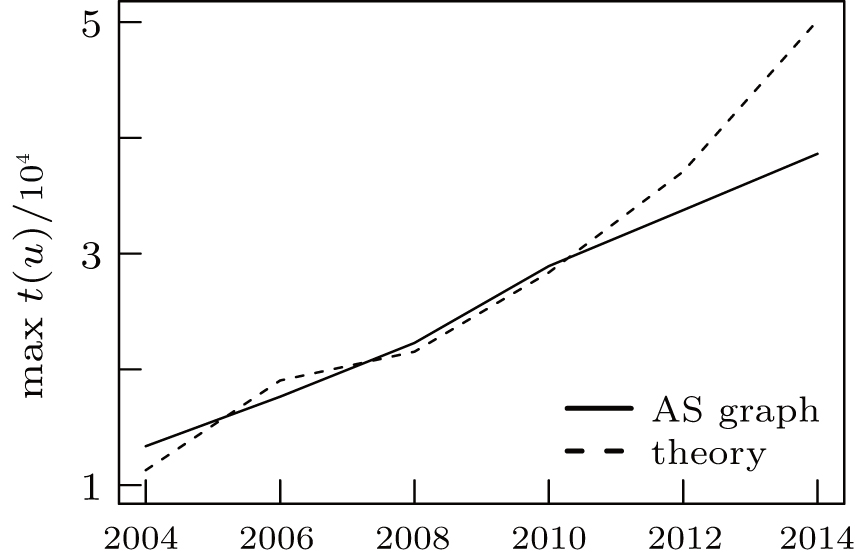 | Fig. 5. Comparing our upper bound for max t(u) based on Corollary 2 with the AS graph over time. |
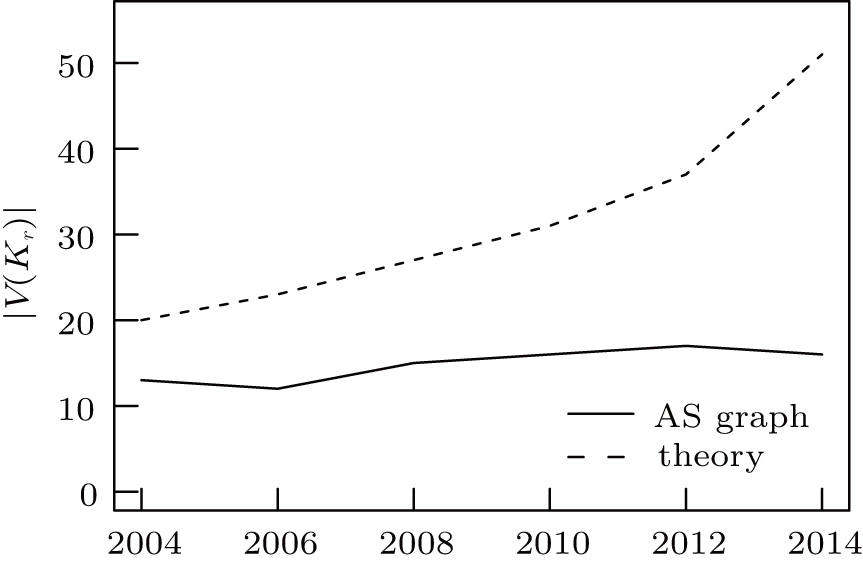 | Fig. 6. Comparing our upper bound for | V(Kr)| based on Corollary 3 with the AS graph over time. |
Our deductive analysis provided us some fresh insights into the AS level topology which, at least according to our best knowledge, are not incorporated in existing AS topology models to a proper extent. While the deductive results give useful hints about the general structure of the AS graph, the high-level nature of these hints is a clear obstacle to convert them into practically usable synthetic AS topologies having at least comparable features with respect to the inductive models. Therefore, in what follows we build a generative AS topology model called YEAS, but besides recovering the usual features of inductive models (e.g., power-law degree distribution, large clustering, small diameter, etc.) we implicitly encode the outcome of our deductive analysis into the node and edge dynamics. Thus at the end of the day we require YEAS to produce Spider-like graphs having correct edge labeling, realistic tier-1 clique size, and realistic placement of the peer edges. The framework of YEAS is based on the recently advocated hyperbolic space models presented in Ref. [20]. What we basically do is dressing a very simple hyperbolic model with our deductive findings.
We distribute the nodes (still representing the ASes) quasi-uniformly on the surface of a hyperbolic disk of radius R. This is done by assigning polar coordinates to each node as
 |
 |
where U1 and U2 are random independent variables distributed uniformly in the interval (0, 1) and α is a parameter controlling the heterogeneity of the layout.
For initialization take node u with the lowest radius and initialize a set 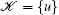
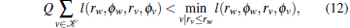 |
then connect w to all nodes in 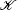
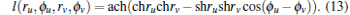 |
In the second phase every node u ∉
First we show that YEAS can readily recover power law degree distribution and high clustering coefficient, which can be observed in the real AS topology. For doing this we show, that our model generates all edges (u, v) for which l(ru, ϕ u, rv, ϕ v) < R but contains edges (u, v) for which l(ru, ϕ u, rv, ϕ v) > R with negligible probability. The first statement trivially follows from the edge creation process itself. The second one is the direct consequence of Eq. (16), that is if the distance between two points l is greater than R, the probability having an edge between these two points is smaller[39] than 
By simply but arguably ignoring (at least from the point of degree distribution and clustering) the negligible number of edges of length larger than R, we end up with a model readily analyzed in Ref. [20]. Nevertheless we recall the most important claims for making our argument self-contained. The expected degree of a node with coordinates r and ϕ is the number of expected points within its R-distance vicinity. Equivalently, this coincides the expected number of points falling inside the intersection of the original R-disk and the disk with radius R and center r, ϕ . In case of 0.5 < α ≤ 1 the degree of a node with radial coordinate r decays exponentially in the function of r (approximately independent from α ), k̄ (r) ∼ e− r/2, while the node density exponentially increases, ρ (r) ∼ eα r. The combination of these two exponentials yields a power law degree distribution P(k) ∼ k− 2 α − 1, and complement cumulative degree distribution F̄ (k) ∼ k− 2α .[32, 33] It can be rigorously shown that there exists a constant lower bound on the global clustering coefficient in hyperbolic random graphs, which confirms the high clustering claimed in such networks.[34]
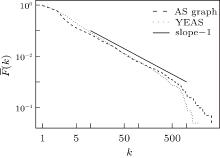
Figure 7 shows the cumulative degree distribution of the real AS graph compared to the degree distribution of YEAS with the setting N = 40000, Q = 5, α = 0.55, β = 0.7, and R = 18.5 (we use this setting for all the simulations from now on). The measured AS graph contains 41203 nodes, so we generated a similar sized topology. The clustering coefficient for the AS graph and for YEAS are both high 0.38 and 0.69 respectively. Table 2 provides additional metrics for comparison.
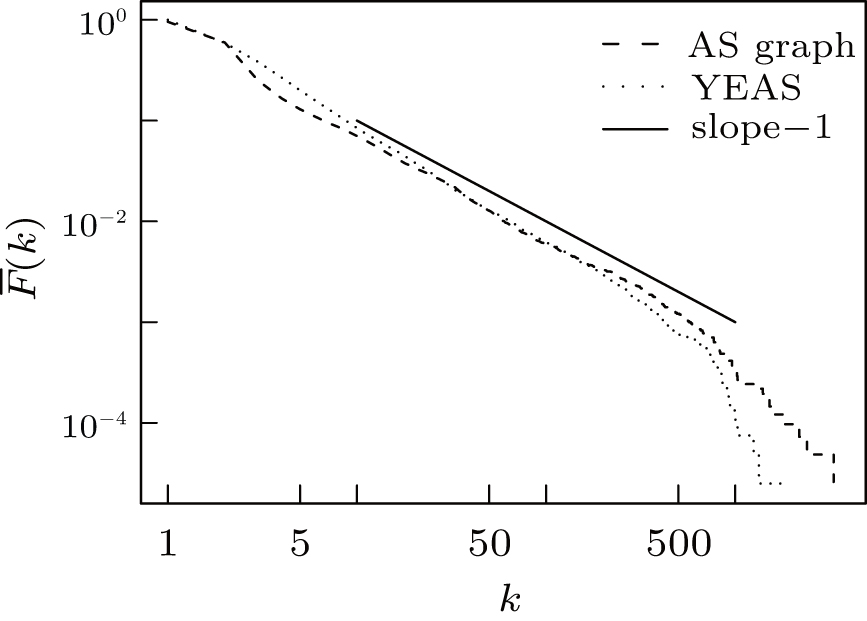 | Fig. 7. CCDF of degrees in the real AS graph and in the YEAS topology. |
| Table 2. Comparison of a YEAS generated topology and CAIDA topology for basic metrics. |
Now turn to quantities almost never tackled by the existing inductive models. The first one will be the expected customer cone size of the nodes and the cone size distribution of the whole network. Building upon these results we will be able to quantify the peering probability of the nodes not residing in
Let p(s, ϕ , r) denote the probability by which node u with radial coordinate s and angle ϕ establishes a provider link to node v with radial coordinate r and angle[39] 0 provided that s > r. Recall that node u establishes a customer– provider link to node v if and only if s > r and node v is the closest to node u. The equivalent geometrical meaning of this condition in the generation model is that none of the other N − 2 points fall within the intersection of the circle with radius s (with the same center as of the R-disk) and the (s, ϕ )-centered circle with radius l(s, ϕ , r, 0). With using elementary hyperbolic geometrical properties, the area of the intersection of these circles can be well approximated (if l(s, ϕ , r, 0) is not very close to 0) as
 |
Now the probability that none of the other N − 2 points fall within this intersection area can be formulated as
 |
where δ = N/AR− disk is defined as the average node density. The approximation of p(s, ϕ , r) is now resulted as
 |
The expected customer cone size as a function of r T̄ (r), r = 0, … , R fulfills the following integral equation:
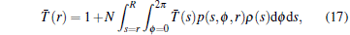 |
where
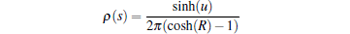
is the node density function. The intuitive explanation of Eq. (17) is the following. The customer cone of a node v with radical coordinate r consists of itself and all other nodes’ cones with larger radial coordinate s > r and any angle coordinate ϕ , which are connected to node v by probability p(s, ϕ , r). For reformulating this equation the following approximations are used:
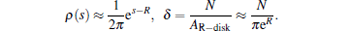
By applying these integral equation becomes
 |
The inner angle integral can be well approximated as e(− s− r)/2/δ . This provides the following (approximate) form of the integral equation:
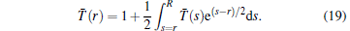 |
The solution of this integral equation gives the function T̄ (r). Unfortunately it can not be solved analytically, however, the solution can be readily characterized as an exponential function. The detailed investigation of the numerical solution confirms this intuition, for a wide range of radial coordinates r, the function T̄ (r) is approximately proportional to e− r.
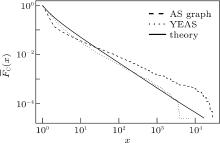
Now, we can analyze the complement cumulative distribution of cone sizes F̄ T(x) = P(T > x). The CCDF of the cone sizes is approximately[40] a power-law with exponent − 1 provided the expected cone size given r is proportional to e− r, that is P(T > x) ≈ x− 1. Figure 8 readily supports these results as the theoretical result goes hand in hand with the outcome of our simulations. Comparing the real AS topology we detect slightly smaller customer cone sizes produced by YEAS. This is definitely the lack of multihoming in the current version of our model. In the AS graph there are many ASes having multiple providers in order to increase reliability, thus many AS contributes to the cone size of multiple ASes. Nevertheless the tendency of the cone size distribution is correctly recovered by YEAS, although the exponent is not exactly the same.
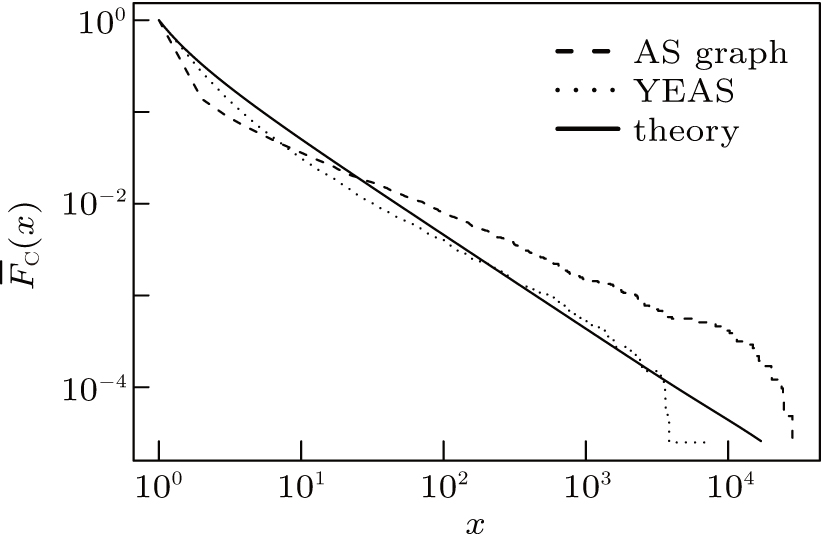 | Fig. 8. CCDF of customer cone sizes in the real AS graph, theory and in the YEAS topology. |
Finally we can turn to analyzing the peering likelihood Ppeering of two nodes having expected customer cone sizes T̄ 1 and T̄ 2. More explicitly, we determine the peering probability in the function of min (T̄ 1, T̄ 2). For this, first the peering probability of two nodes with radial coordinate r1 and r2 in the function of max(r1, r2) is calculated, then the function r(T̄ ) (the inverse function of T̄ (r)) is applied. Without loss of generality, assume that r1 < r2. Given r2, the nodes with smaller radial coordinates r1 < r2 lie within the circle with radius r2 and center 0. Clearly, among these nodes those have peer edges to node r2 which lie in the intersection of this disk and the r2 centered R-radius disk. Therefore, due to the uniform distribution of nodes the peering probability is the ratio of this intersection area and the area of the 0-centered r2 radius disk. Evidently, the peering probability is 1, if r2 < R/2, because in this case the 0-centered r2 disk is fully contained by the r2-centered R-radius disk. If r2 > R/2 it can be shown by elementary hyperbolic geometry that
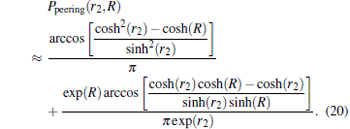 |
The more detailed analysis of this approximation discloses that it is well approximately proportional to e− r. From this a simple enough approximation can be obtained as
 |
It apparently follows that
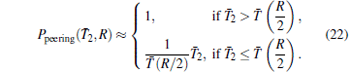 |
This means that the likelihood of peer edges of an AS having a customer cone size to other ASes having larger customer cone sizes is proportional to its cone size, and this likelihood tends to be 1, if the cone size falls below a certain limit. This characteristic property is also confirmed by our simulations shown in Fig. 9 and coincide with results measured on the real AS topology.
The above theoretical results show that YEAS generates realistic complex networks with proper degree distribution, clustering and diameter, yet incorporating our deductive findings as the synthesized topologies are Spider-like (trivially follows from the generation process), with tunable tier-1 clique (through the Q parameter) and realistic peering likelihood.
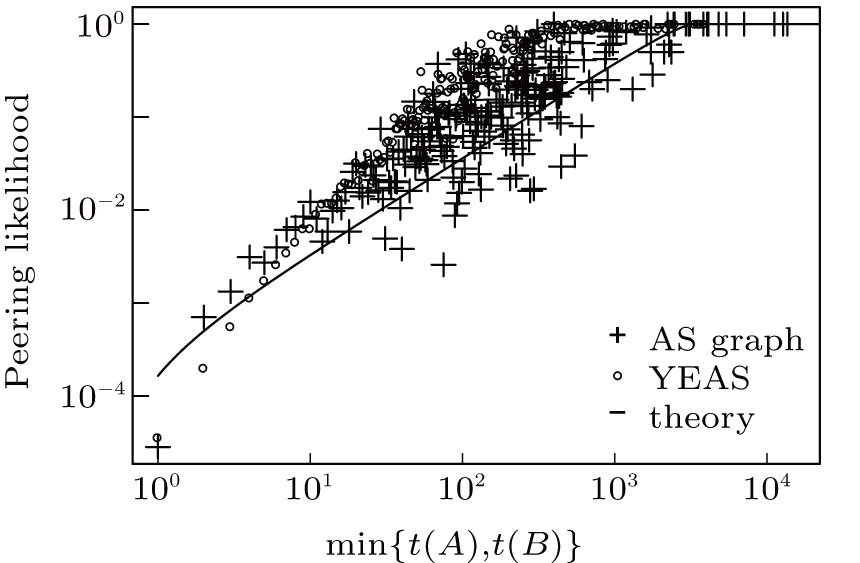 | Fig. 9. Peering likelihood between ASes as the function of their customer cone size (here we exteneded Fig. 4 by adding results about the YEAS generated topology). |
In this paper we have proposed a deductive approach for revealing network dynamics on the Internet’ s AS level topology formation. We believe that this approach allows us to make some reasonable predictions about the structural changes of complex networks and facilitates the design of proactive algorithms. The first step for this is to find the correct premises, which is not trivial, but the findings of other complex networks can also be used as a starting point and even can reinforce each other. For example it is possible that valley-free information flow is not just an Internet specific feature. At the highest level it says: “ a minor node cannot serve the demand between two major nodes” , which can also be used in neural or in social networks (after careful consideration, of course).
So in accordance to this approach we made premises about the AS level Internet that have provided us the possibility of theoretical analysis and let us improve our interpretation of the AS system as provide insights complementary to the existing inductive models. One can question which other directions we should look for more premises that can shed more light on the AS level topology. Our first suggestion would be to dig more deeply into the interdomain route selection process and incorporate e.g., AS path length or various sources of traffic engineering in the premises. On the other hand we argue that the basic inter-AS business rules and other technological constraints e.g., the role of IXP-s in the AS– AS connectivity, the multihoming opportunities or security aspects (either in the pure form of supporting secure BGP) can be rich sources of usable premises for future works.
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
|
| 9 |
|
| 10 |
|
| 11 |
|
| 12 |
|
| 13 |
|
| 14 |
|
| 15 |
|
| 16 |
|
| 17 |
|
| 18 |
|
| 19 |
|
| 20 |
|
| 21 |
|
| 22 |
|
| 23 |
|
| 24 |
|
| 25 |
|
| 26 |
|
| 27 |
|
| 28 |
|
| 29 |
|
| 30 |
|
| 31 |
|
| 32 |
|
| 33 |
|
| 34 |
|
| 35 |
|
| 36 |
|
| 37 |
|
| 38 |
|
| 39 |
|
| 40 |
|