
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
A local fuzzy method based on “p-strong” community for detecting communities in networks
[Shen Yi1, 2, Ren Gang1, †,  , Liu Yang2, Xu Jia-Li2]
, Liu Yang2, Xu Jia-Li2]
, Liu Yang2, Xu Jia-Li2]
|
|


† Corresponding author. E-mail:
Project supported by the National Natural Science Foundation of China (Grant Nos. 51278101 and 51578149), the Science and Technology Program of Ministry of Transport of China (Grant No. 2015318J33080), the Jiangsu Provincial Post-doctoral Science Foundation, China (Grant No. 1501046B), and the Fundamental Research Funds for the Central Universities, China (Grant No. Y0201500219).
In this paper, we propose a local fuzzy method based on the idea of “p-strong” community to detect the disjoint and overlapping communities in networks. In the method, a refined agglomeration rule is designed for agglomerating nodes into local communities, and the overlapping nodes are detected based on the idea of making each community strong. We propose a contribution coefficient 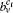
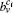
Real systems and networks such as the World Wide Web (WWW),[1] collaboration networks,[2] metabolic networks,[3] etc., are far from being purely random, within which the distribution of link density is inhomogeneous both locally and globally. This leads to a most significant property in them, that is, community or modular structure. This property allows us to have an in-depth insight into real systems and obtain more useful statistical information than on simple nodes. So far, based on the inhomogeneous distribution of connections in real networks, a widely accepted definition of communities is that communities are the groups of nodes such that the connections in the same group are denser than between groups.[4] The importance of the community identification task has been addressed in many research fields. For example, in protein–protein interaction networks, the proteins with a similar functionality tend to be observed in similar chemical reactions. In parallel computing, how to allocate tasks to processors to minimize communication cost is remarkably important.
In the past several years, many approaches have been proposed for community detection.[5–8] These approaches can be classified as several categories,[5,6] such as divisive algorithms, optimization methods, dynamic algorithms, etc. Among these methods, the methods based on the optimization of the modularity function Q[4] usually have the highest accuracy[5] because the modularity function Q is proposed based on the definition of communities. It is known that the Q is a global function and the corresponding method based on optimizing it must be a global method. Before using these optimizing methods, we need to know the topology of the whole network in advance. However, for some large and dynamic real networks such as the Internet or WWW, it is difficult to obtain their global topology knowledge since they evolve very quickly.[7] Therefore, a practical way may be local methods, and by which, a particular community starting with an initial node in a network can be discovered. Recently, several researches focused on designing efficient local methods, such as the Clauset[9] method and the Bagrow[10] method. Other local or semi-local methods that rely on a priori network assumption have been proposed,[11–13] and they are accurate only when used as a part of the global method.[10] They are Luo, Wang, and Promislow (LWP),[11] the Flake and Lawrence method,[12] Bollt method,[13] etc. Among these methods, the Bagrow method has the highest accuracy and the lowest computational cost.[10] It is worth noting that the above local methods aim to identify disjoint communities.[5] In fact, a real network is usually composed of several communities with nodes overlapping with each other, and these communities and nodes are called overlapping communities and nodes,[13] respectively. Currently, the overlapping community detection methods are mainly categorized into two types: crisp and fuzzy.[5] For crisp overlapping communities, each node belongs to one or more communities with equal strength.[5] For a fuzzy overlapping community, each node belongs to more than one community with different strengths.[5] The belonging coefficients or fuzzy coefficients measure how an overlapping node is distributed among different communities. The value of the belonging coefficient is between 0 and 1 representing the strength of membership of a node v to a community. Meanwhile, for node v, the sum of belonging coefficients for all communities is 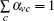
In this paper, we propose a local method to detect the disjoint and overlapping communities. The method is based on the idea of “p-strong” community. In the method, a refined agglomeration rule is designed for agglomerating nodes into local communities accurately, and the overlapping nodes are detected based on the idea of making each community strong. We propose a coefficient 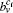
Before presenting our method, it is necessary to present the main idea of several existing local methods, such as the Clauset method[9] and the Bagrow method,[10] which can help to understand the implementation and advantages of our method we presented in Subsection 2.2.
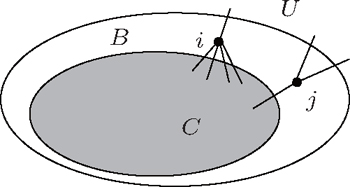
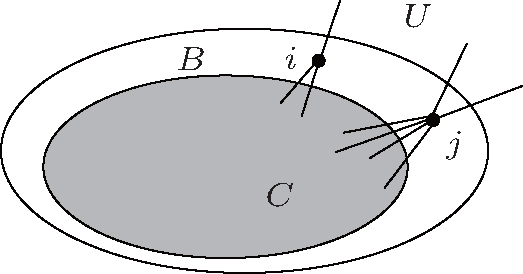
For a network, the two local methods divide it into three parts, i.e., the detected community C including a starting node, the region B in which all nodes have neighbors in C, and the region U that is unknown, as figure
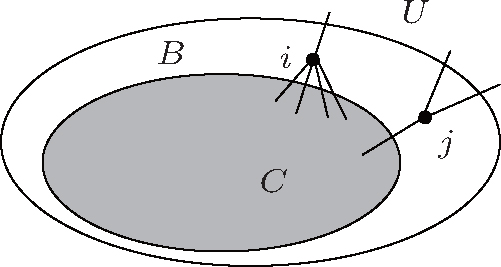 | Fig. 1. Community C surrounded by a boundary of explored nodes B which is adjacent to C. U represents the unknown potential region. |
The Clauset algorithm[9] determines a local modularity for agglomerating nodes, which is rewritten by Bagrow as[10]
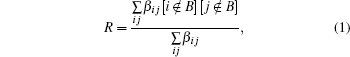
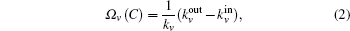
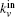
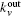
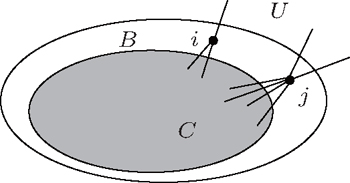
From the above, we can see the basic idea of the local community detection methods is how to agglomerate the nodes into communities. In Fig.
 | Fig. 2. Two or more nodes with the same value of kin/kout or the same smallest Ω. |
We can solve the problem based on the idea of making the community strong. We use Min and Moutto denote the numbers of edges internal and external to C[21]
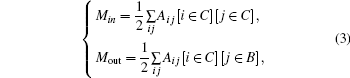

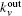

It can be seen from Eq. (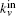
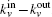
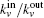
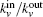
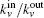
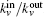
This process runs until a stopping criterion is satisfied. We use the “p-strong” criterion as the stopping criterion. For a completely strong community C, each node in C has more neighbors inside than outside, which can be written as
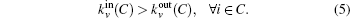
However, this condition is usually not satisfied especially for real networks. Hence, a low condition can be relied on. For a community, if only a fraction p of the nodes in C satisfy Eq. (
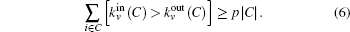
The detected C is maintained when the community ceases to be strong. Then we can address the C by calculating the local modularity.
It is known that the modularity of a network can be increased if we agglomerate the overlapping nodes into their corresponding overlapping communities.[5] In other words, for an overlapping node, all its corresponding overlapping communities become “stronger” if we agglomerate the node into them respectively. However, the contributions to different overlapping communities may be different. This is in accordance with the idea of fuzzy coefficient that is used to measure the extent to which an overlapping node belongs to its overlapping community. Based on this idea, we can extend our method to detect the overlapping nodes and their overlapping communities by using the fuzzy coefficients. In the agglomerating process of our method, the overlapping nodes will be agglomerated into different overlapping communities for obtaining “stronger” communities. Therefore, after agglomerating all the nodes, the overlapping nodes can be found. In order to know the individual contribution of an overlapping node v to one of its community Ci, we can remove v from Ci and re-agglomerate it into Ci again. Then increments of ΔMv(Ci) and the community “strong” parameter 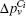


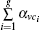
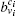
In our method, the kin/kout of a node can be calculated with the knowledge of node degrees, and the cost of agglomerating |C| is O(|C|d2log|B|) for a network with average degree d. This is similar to the Bagrow method. Moreover, the cost can be written as O(|C|log|B|) for a sparse network. The overlapping nodes and their overlapping communities can be found after all the nodes have been agglomerated. The cost of obtaining the fuzzy coefficients depends on the number of the overlapping nodes and their overlapping communities. For a network that has On overlapping nodes, the cost of obtaining the fuzzy coefficients is 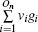
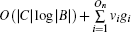
For detecting disjoint communities, we can see that the cost of our method is linearly increasing with the augment of network size which is smaller than those of many existing methods.[5] For detecting the overlapping communities, our method has lower computation cost than many global overlapping-community detection methods and fuzzy methods.[5] Although our method cannot provide the global view of fuzzy coefficients for all the nodes in a network, the key overlapping nodes with fuzzy coefficients and their overlapping communities can be obtained quickly by our method. These overlapping nodes are very important in real networks since they usually act as key media between different functional groups,[4] such as the gateways in computer networks, the relationship coordinators in social networks, the interdisciplinary papers in citation networks, etc.
In this section, we apply our method to several computer-generated networks including the Girvan and Newman (GN) networks[4] and a set of Lancichinetti, Fortunato and Radicchi (LFR) networks[22] with known community structure. Then, several real networks are investigated.
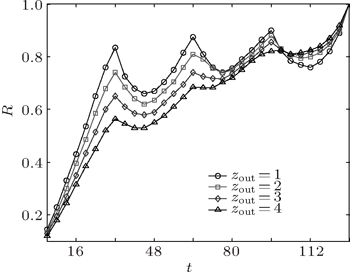
We first apply our method to the well-known GN networks[4] to show the implementation of our method. In each GN network, 128 nodes are divided into four groups. Each group has 32 nodes and each node has z = zin + zout = 16 edges, where zout is the edges that connect the nodes outside its group and zin is edges that connect the nodes inside its group[4]. We use local modularity R to show the agglomeration process. In the agglomeration process, the local modularity R changes with the number of agglomerations t. Figure
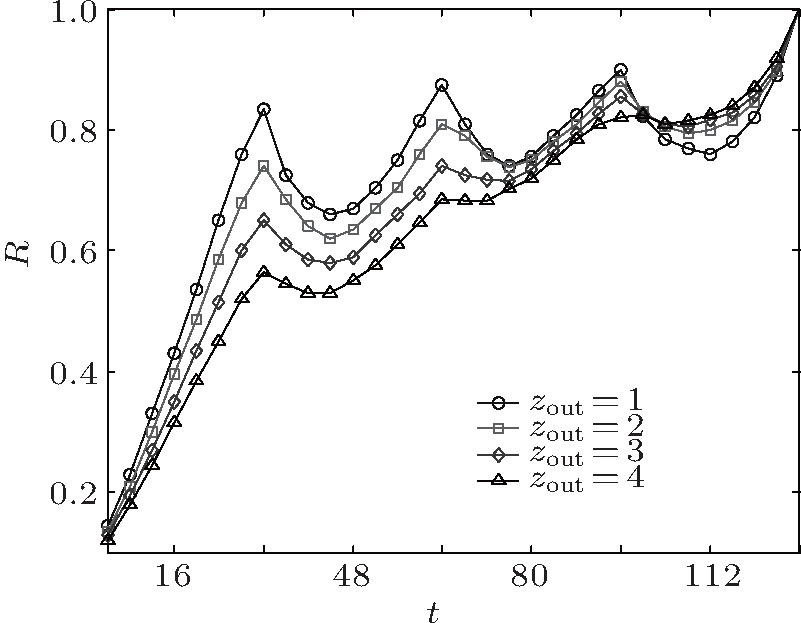 | Fig. 3. Results of our method on the GN networks. |
We use the normalized mutual information (NMI)[6] to investigate the accuracy of our method. The NMI measures the difference between the true partition A and found partition B, which is written as[6]
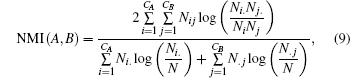
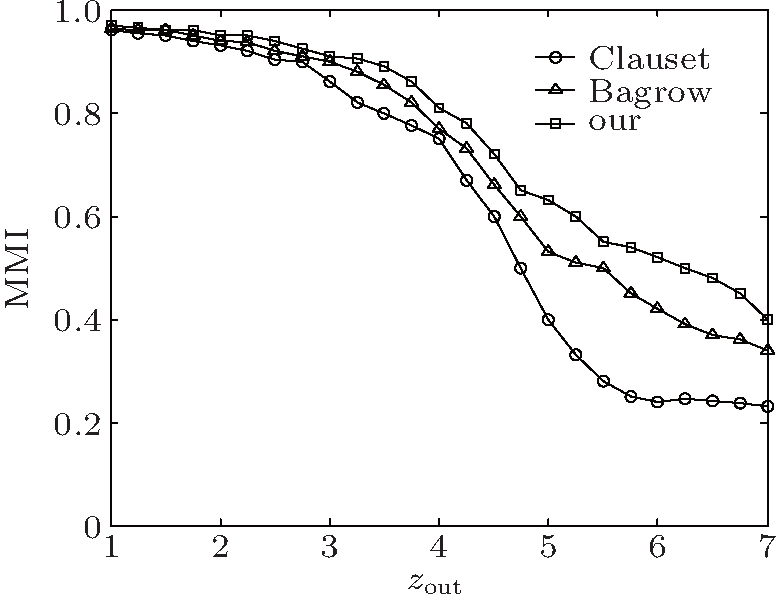 | Fig. 4. Results on the GN networks each as a function of zout, each datum point is obtained by averaging over 400 networks. |
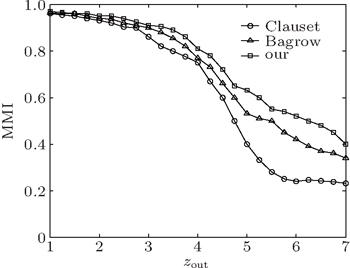
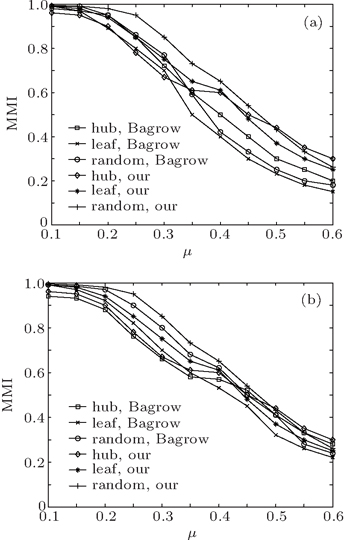
The topology of GN networks is unrealistic since real networks show heterogeneous distributions of community sizes and node degrees. In this subsection, we use a set of realistic benchmark networks called LFR benchmark networks[22] to test our method. The LFR networks have heterogeneous degree distributions and community sizes, and allow communities to overlap, which are in accordance with the features of real networks, and have been widely used for testing the community detection methods in recent years.[5,23–26] The adjustable topology parameters for the LFR benchmark networks are network size N, average degrees ⟨k⟩, maximum degrees kmax, minimum and maximum community size cmin and cmax, the degree distributions γ, the community size distributions β, the mixing parameter μ, the number of communities each overlapping node belongs to om, and the number of overlapping nodes on.[22] In order to detect the overlapping communities and nodes and make comparisons with other well-known fuzzy overlapping community detection methods, such as Fuzzyclust[27] and NMF,[17] we first investigate our method on the LFR networks without overlapping nodes to compare with the existing local methods in the detection of disjoint communities. The LFR networks have the mixing parameter μ in a range from 0.1 to 0.6, ⟨k⟩ = 24, cmin = 16, and cmax = 64, γ = 2.5, β = 1.5, and N = 500. We start our method on the leaf nodes, hub nodes, and randomly selected nodes separately. In Fig.
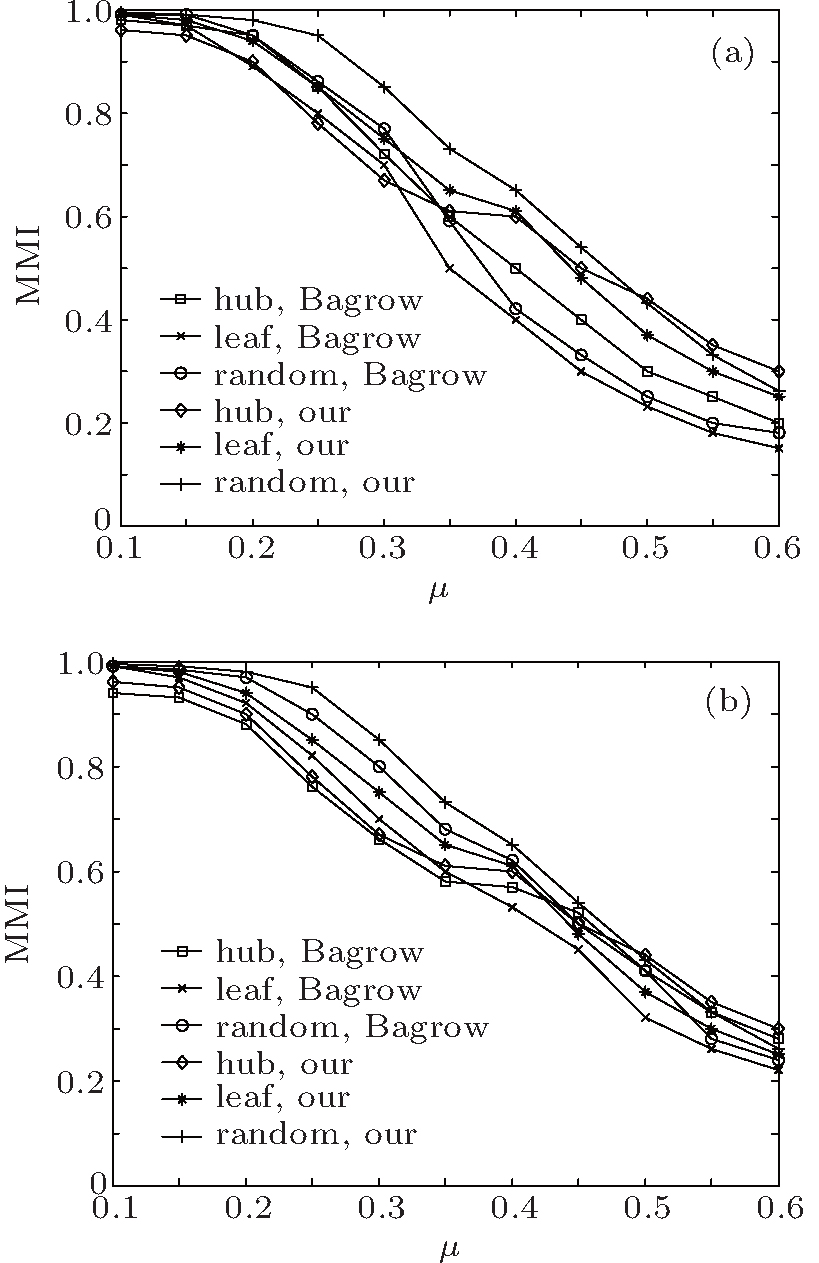 | Fig. 5. Results measured by NMI on the LFR networks, in which each datum point is obtained by averaging over 400 networks, showing the comparisons of the results from our method with the results from (a) the Clauset method and (b) the Bagrow method. |
From Fig.
Next, we compare our method in detecting the overlapping nodes and their belonging coefficients. We generate the LFR networks with the mixing parameters μ = 0.1 and μ = 0.3, and the ratio of overlapping nodes on/N ranging from 0 to 1, and om = 2 for on/N > 0. The rest of the parameters have been presented above. We use the fuzzy Rand index (FRI) measure (named after William M. Rand)[6] to quantitatively compare the known-fuzzy division with the fuzzy division obtained by our method. Figure
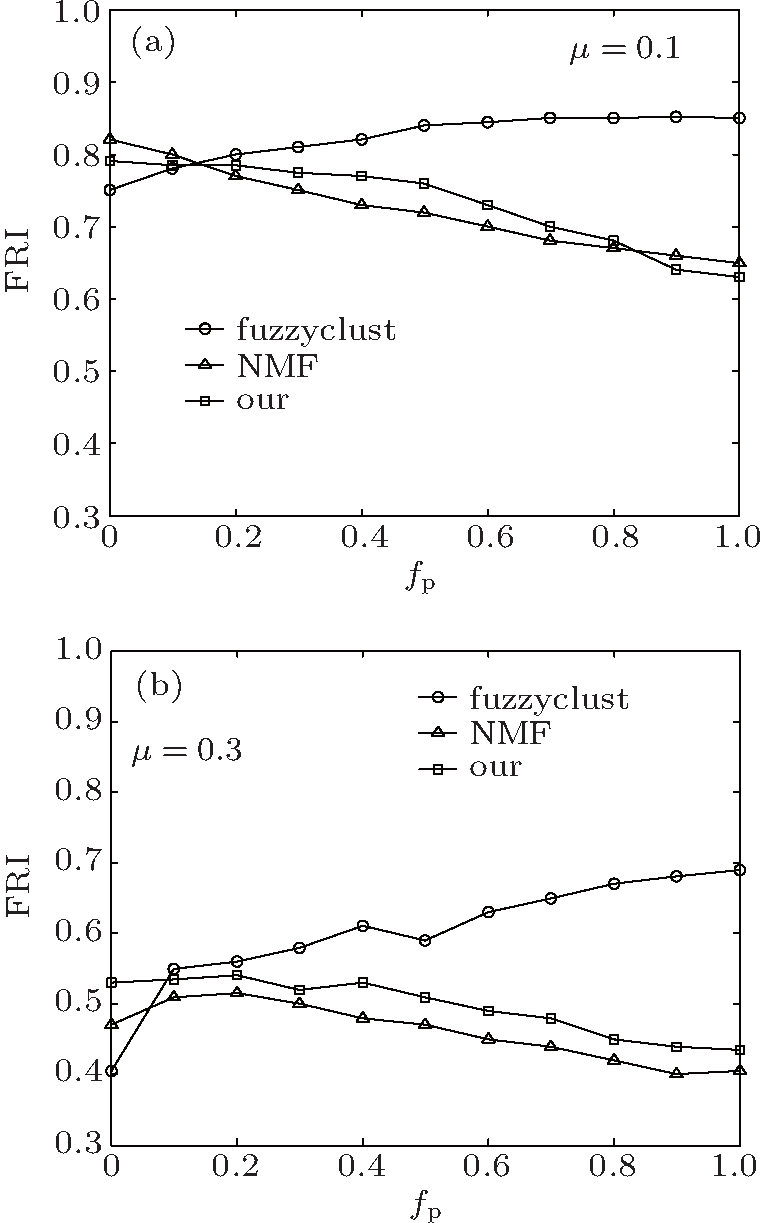 | Fig. 6. Results measured by FRI versus the ratio of overlapping nodes fp. Each datum point is obtained by averaging over 400 realizations. (a) μ = 0.1 and (b) μ = 0.3. |
In this section, several real world networks are investigated including the Zachary karate network,[28] the American college football network,[2] an electronic circuit network,[29] and a transcriptional regulation network of Escherichia coli.[29] The Zachary network has 78 links representing friendships among 34 members.[28] The network has been widely used to test the community detection methods, and is usually divided into two groups each with 16 nodes and 18 nodes. The American college football network represents the schedule of games between American college football teams in a single season, which has 115 teams and 616 competitions. The network does not have an apparent center node and is usually divided into 8–12 team communities.[4] The circuit network has 512 nodes and 819 edges in which nodes are electronic components and edges are wires.[29] In the transcriptional regulation network, nodes represent operons and an edge connecting two nodes A and B if A activates B. The transcriptional regulation network has 423 nodes and 519 edges.[29]
For making fair comparisons between the local methods, the initial starting node for the local methods is randomly selected. Each method runs 20 times on the same networks and the result is averaged. To make comparisons in the detection of disjoint communties, the SA method,[30] which has been proved to have high accuracy,[5] is also investigated. Table
| Table 1. Results of the detection of the disjoint communities in the real networks. The values of the number of disjoint communities Cn and the global modularity Q are presented. . |
As Table
| Table 2. Results of the detection of the overlapping communities in the real networks. On is the number of overlapping nodes, and the corresponding value of the modularity Q is also given. . |
Local community detection methods have the advantages of low computation cost and not needing to know the whole network topologies in advance. In this paper, according to the idea of “p-strong” community, we propose a local method for detecting the disjoint communities and overlapping communities. In the method, a refined agglomeration rule is designed for agglomerating nodes into local communities accurately, and the overlapping nodes are detected based on the idea of making each community strong. A coefficient 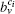
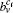
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | |
| 17 | |
| 18 | |
| 19 | |
| 20 | |
| 21 | |
| 22 | |
| 23 | |
| 24 | |
| 25 | |
| 26 | |
| 27 | |
| 28 | |
| 29 | |
| 30 |