















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Rapid identifying high-influence nodes in complex networks
[Song Boa) , Jiang Guo-Ping†b)  , Song Yu-Rong
, Song Yu-Rongb) , Xia Ling-Linga) ]
, Song Yu-Rong

†Corresponding author. E-mail: jianggp@njupt.edu.cn
*Project supported by the National Natural Science Foundation of China (Grant Nos. 61374180 and 61373136), the Ministry of Education Research in the Humanities and Social Sciences Planning Fund Project, China (Grant No. 12YJAZH120), and the Six Projects Sponsoring Talent Summits of Jiangsu Province, China (Grant No. RLD201212).
A tiny fraction of influential individuals play a critical role in the dynamics on complex systems. Identifying the influential nodes in complex networks has theoretical and practical significance. Considering the uncertainties of network scale and topology, and the timeliness of dynamic behaviors in real networks, we propose a rapid identifying method (RIM) to find the fraction of high-influential nodes. Instead of ranking all nodes, our method only aims at ranking a small number of nodes in network. We set the high-influential nodes as initial spreaders, and evaluate the performance of RIM by the susceptible–infected–recovered (SIR) model. The simulations show that in different networks, RIM performs well on rapid identifying high-influential nodes, which is verified by typical ranking methods, such as degree, closeness, betweenness, and eigenvector centrality methods.
The highly influential individuals in complex systems play a critical role in the dynamics on complex systems, such as the target population decision for immunization, the optimal spreaders for information diffusion in social networks, [1] the important breakers in power grid. Identifying those influential nodes and finding effective ranking methods of node influence are very important in the field of complex networks.[2– 4]
In the last few years, various methods[5] have been proposed for studying the “ importance” of nodes in complex networks, including the ranking methods based on nodes’ neighbors, such as degree centrality[6] and k-shell decomposition, [7] based on path, such as betweenness centrality[8] and closeness centrality, [9] based on eigenvector, such as the eigenvector centrality, [10] PageRank[11] and HITs algorithm, [12] and based on nodes’ removal and shrinkage, such as the shortest distance method of node deletion[13] and node contraction method.[14] These methods have been proved to be effective for node ranking through a large number of experiments. Based on these classic methods, many new improved methods were proposed, such as the semi-local centrality, [15] Leader Rank, [16] and some new ones based on the network topology.[17– 19] Measures to evaluate the ranking methods are usually based on the dynamics, [22] the robustness, [2] and fragility of networks.[23] The influence of nodes is judged by its effects on other node statuses in the networks, the specific network structures and functions. How to design a ranking measure by considering both universality and effectiveness in complex networks has become one of the key problems in complex networks research.
Currently, most of the researchers focus their attention on finding the most effective method of node ranking. In fact, the existing networks show many new characteristics which cannot be ignored in ranking nodes. 1) Extensive. With the development and progress of science and technology, we are now in the era of big data, and the scales of networks are growing fast. In this case, even the simplest ranking method will be time-consuming. 2) Adaptive. The structures of many realworld networks are adaptively changing depending on the state of nodes, [24] the node orders ranked previously may fail to sort in the current time. 3) Time-sensitive. Dynamic behaviors in real networks are time-sensitive, which means that we need to find the influential nodes in a limited time to be applied to the dynamics.
The main purpose of identifying influential nodes is to find a fraction of top influential nodes for application, so it is not necessary to rank all nodes. Therefore, instead of ranking all nodes in the network, we focus on finding a fraction of high-influence nodes in the network. In this paper, we propose a rapid identifying method (RIM) based on node degree and network structure to identify high-influence nodes in networks. Moreover, we use the susceptible– infected– recovered (SIR) model, [25] in which the high-influence nodes are treated as spreaders to evaluate the performance of our method. The simulations in different networks show that our method performs well on rapid identifying high-influence nodes.
The rest of the present paper is organized as follows. In Section 2, we present our new method called RIM. The SIR model is used to evaluate the performance of the proposed method in Section 3. The simulations are given to demonstrate the proposed method in Section 4. Finally, the conclusions are given in Section 5.
Among different centrality measures, each measure has its scope of application and its own characteristic. Here we briefly introduce some classic and authoritative methods, which will be used in experimental analysis in Section 4.
A simple method based on node local properties is degree centrality, namely, the larger degree a node is, the higher influence the node will obtain. Compared with the method based on local properties of nodes, the method considering the global information will give better ranking results, such as betweenness centrality and closeness centrality.
Betweenness is defined as the fraction of shortest paths between node pairs that pass through the nodes of interest. For a network with N nodes, the betweenness centrality of node i, denoted by BCi is
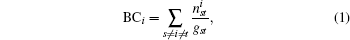
where gst is the number of shortest paths between nodes s and t, and
Closeness of node i is defined as the reciprocal of the average geodesic distances to all other nodes of I, i.e.,
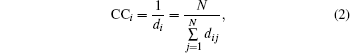
where dij is the geodesic distance between i and j.
Another widely employed centrality measure, which can be observed in a natural extension of degree centrality, is eigenvector centrality. Eigenvector centrality[10] is based on the more subtle notion that a node should be viewed as being influential if it is linked to other nodes which are influential themselves. The eigenvector centrality ECi of a node i is defined as being proportional to the sum of the eigenvector centralities of the nodes that node i is connected to, i.e.,
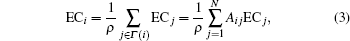
where ρ is a constant. It is also assumed that the eigenvector centrality of each node is non-negative (ECi ≥ 0), for all i.
For a network G with N nodes and M edges, calculating the shortest paths between all pairs of nodes encounters the complexity O(N3) with the Floyd’ s algorithm.[26] For a sparse graph, it will be more efficient with Johnson’ s algorithm, [27] which takes O(N2 logN + NM). For unweighted networks, calculating betweenness centrality encounters O(N2M) using Brandes’ algorithm.[28]
With the in-depth study on node influence, a growing number of methods[17– 21] have been proposed. Most of these methods are the improved versions of the previous methods and achieve the desired effect. Once the nodes’ influence has already been sorted, the most influential nodes will be used in many fields, such as disease control and prevention in the population, information dissemination in social networks, important power unit protection in the power grid networks, etc. Those applications of influential nodes have gradually improved our lives.
As the era of big data has begun, some novel characteristics have come into being in networks which were ignored in the past, such as extensive, adaptability and time-sensitive. When those characteristics are considered, we have reasons to suspect the availability of the ranking measures. First, rapidly increasing sizes of networks make the information harder to collect, which severely restricts the measures based on the global information. At this point, measures based on local information have greater practical significance. Second, even just taking local characteristics into consideration, the calculation of all nodes’ centralities is very time-consuming or even not feasible. Meanwhile, the dynamics in networks are very time-sensitive, which means that we need to identify the influential nodes in a very short time. Additionally, many realworld networks are characterized by adaptive changes in their topology depending on the state of their nodes.[24] The sequence of nodes we ranked in the previous time may fail to sort in the present time.
In order to find the influential nodes in less time, we focus our attention on identifying a fraction of high-influence nodes instead of ranking all nodes. Considering the uncertainties of network scale and topology, and the timeliness of dynamic behaviors in real networks, we propose an RIM, which is a method of rapidly identifying high-influence nodes based on the nodes’ local properties. Introduced into this method are the following procedures:
(i) m nodes are randomly chosen as the first source nodes, denoted as si, i = 1, 2, … , m;
(ii) find the highest-degree neighbor of each si as the second source nodes, denoted as si_N(1), i = 1, 2, … , m, then find the highest-degree neighbor of each si_N(1) as the third source nodes; according to this method, we will stop when we find the (j + 1) source nodes, denoted as si_N(j), i = 1, 2, … , m. In this way, we will find m × j nodes, denoted by si_N(j), i = 1, 2, … , m, J = 1, 2, … , j. Note that the first source nodes si are not counted, and in the process of finding the highestdegree neighbor of si_N(j), if the highest-degree neighbor of si_N(j) has been found before, we will find the second highestdegree neighbor of si_N(j);
(iii) rank the m × j nodes according to their degrees, and choose the top-j nodes Tnj as the target nodes (Tnj ∈ si_N(j)).
Considering the fact that the degree is one of the simplest but most important local characteristics of nodes, we can realize our method without knowing the global information about the network. In addition, the close relationship among hubs (high-degree nodes) makes our method effective.
Since the calculating of node i’ s degree requires traversing node i’ s neighborhood within one step, the computational complexity of degree centrality is O(N〈 k〉 ), [15] where 〈 k〉 is the average degree of the network. In RIM, we can find m × j target nodes, so the computational complexity of RIM is O(mj〈 k〉 ). Since 〈 k〉 ≪ N, j ≪ N, m ≪ N, we can know that RIM uses much less time than ranking all nodes in the network.
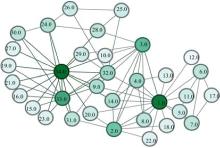
Take Zachary’ s karate club network[29] for example. There are 34 nodes and 78 edges in the karate network. As shown in Fig. 1, node color becomes deeper as the degree of the node increases. We set m = 1, j = 5, and choose the nodes from the 2nd step to the 6th step as the target nodes. The nodes found by RIM in the karate network and the nodes’ corresponding rankings by degree centrality (DC), betweenness centrality (BC), closeness centrality (CC) and eigenvector centrality (EC) methods for one implementation are shown in Table 1. The computational complexity of degree centrality is O(N〈 k〉 ), and the computational complexity of RIM is O(mj〈 k〉 ). We can see that mj〈 k〉 < N〈 k〉 .
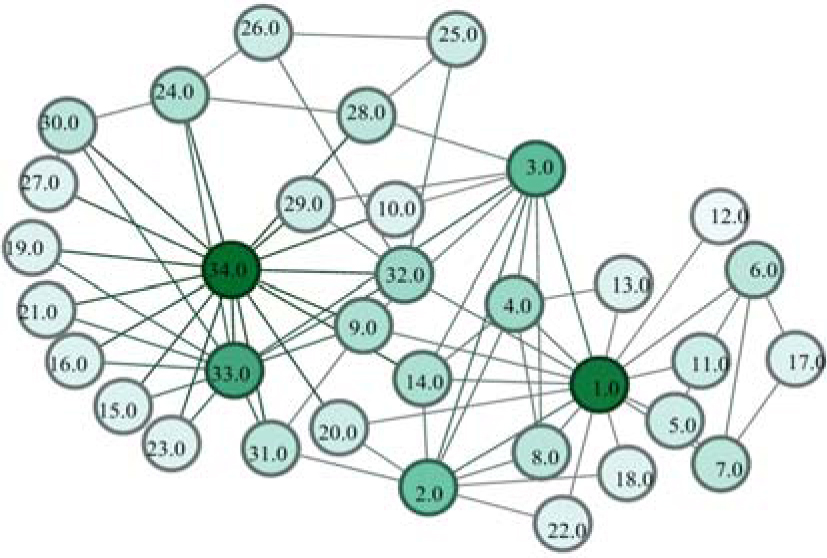 | Fig. 1. Zachary’ s karate club network. |
Table 1 shows the nodes found by RIM in the karate network in one experiment and the nodes’ corresponding rankings by different centrality methods. According to the statistics of node rankings, we can see that the target nodes found by RIM have high influence. Almost all top-5 ranking nodes from different methods can be found by RIM in one single experiment. Meanwhile, the appearance number of node n (OTn) is counted in 500 experiments. In Table 1, it is shown that nodes 1, 3, 33, 34, having high influence verified by different centralities, can almost be found in each of the experiments (OT1 = 500, OT3 = 500, OT33 = 489, OT34 = 489).
| Table 1. Nodes found by RIM in the karate network and their corresponding rankings obtained from DC, BC, CC and EC methods. |
The spreading model is often used for evaluating the performances of the ranking methods.[15, 16] In the following, we use the SIR model to investigate the performances of our method (RIM) in different networks. In the SIR[25] model, there are three states for a node: i) susceptible (S), ii) infected (I), and iii) recovered (R). S individuals are susceptible to (not yet infected) the disease, I individuals have been infected and are able to spread the disease to susceptible individuals, and R individuals have been recovered and will never be infected any more.
To investigate the influences of target nodes in networks, we set these nodes to be infected initially. The f(t) and F(t) represent the proportion and the number of recovered nodes in the steady state respectively, which can be considered as the indicators to evaluate the influence of the nodes.
In our experiments, we use different artificial networks and real networks to test the effectiveness of our method. The real networks include Facebook, Email and Neural networks. In the Facebook network, we use the Facebook network data of Caltech from a single-time snapshot in September 2005. Only intra-college links are included. There are a total of 769 individuals in this Facebook network, but here we only consider the largest component with 762 individuals. In the email network, the network of e-mail interchanges between members of Rovira i Virgili University (Tarragona)[30] is used. In the neural network, we use the neural network of C. Elegans, where the data were compiled by Watts and Strogatz.[31]
The basic topological properties of the networks are shown in Tables 2– 4. In these Tables, N and L are the total numbers of nodes and links, 〈 k〉 denotes the average degree, 〈 d〉 is the average shortest distance, and C and r are the clustering coefficient[31] and assortative coefficient, [32] respectively.
| Table 2. Basic topological properties of the real networks. |
| Table 3. Basic topological properties of the artificial networks with different structures. |
| Table 4. Basic topological properties of the artificial networks with different sizes. |
We use different ranking methods to verify the effectiveness of our method. At first, in order to show the results clearly, only one node is randomly selected as the first source node in each implementation, and 10 nodes are found according to our method, which means m = 1, j = 10. After n implementations, the results of node ranking and the average ranking of n implementations in each step t by their corresponding BC, CC, DC, and EC methods in different artificial networks are shown in Figs. 2– 9, including scale-free (SF) networks with different values of the clustering coefficient C (Figs. 2– 5) and the coefficient of assortativity r (Figs. 6– 9).
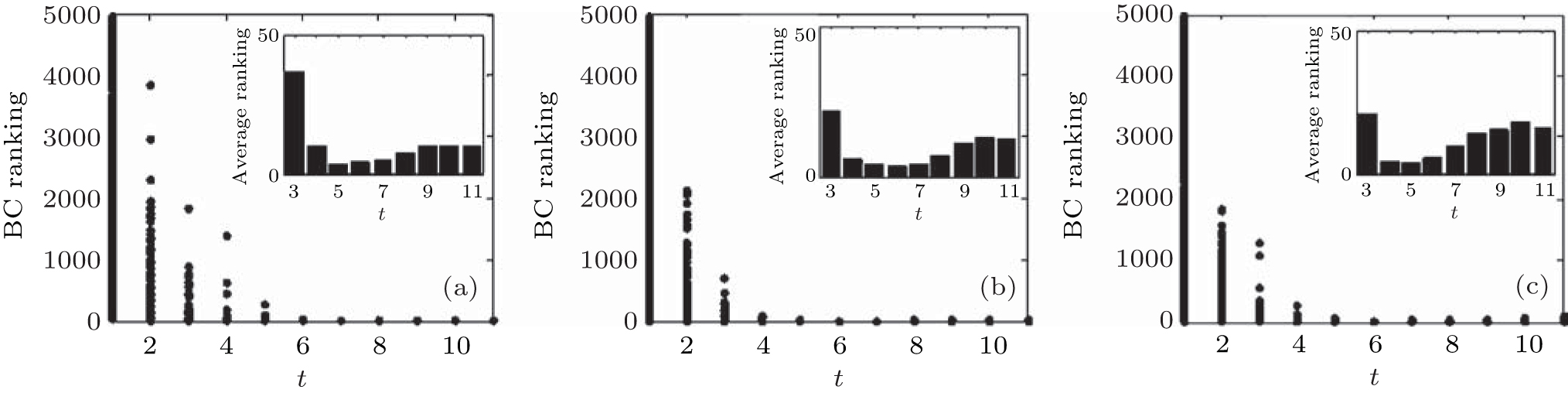 | Fig. 2. Target node rankings and the average ranking of 500 implementations by BC for SF networks with the clustering coefficient C = 0.009 (a), 0.165 (b), and 0.542 (c). |
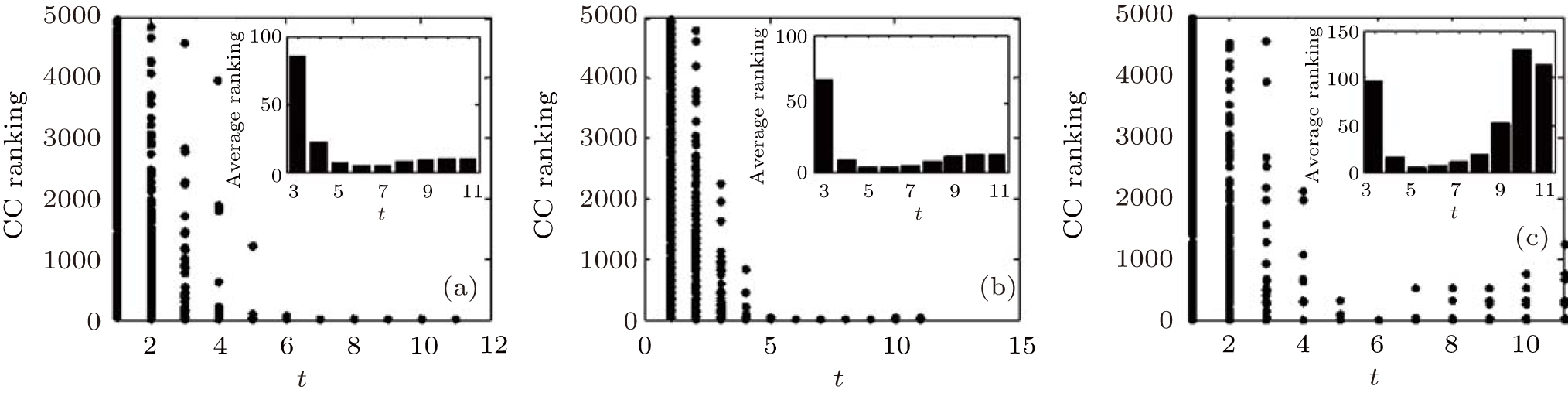 | Fig. 3. Target node rankings and the average ranking of 500 implementations by CC for SF networks with the clustering coefficient C = 0.009 (a), 0.165 (b), and 0.542 (c). |
 | Fig. 4. Target node rankings and the average ranking of n = 500 implementations by DC for SF networks with the clustering coefficient C = 0.009 (a), 0.165 (b), and 0.542 (c). |
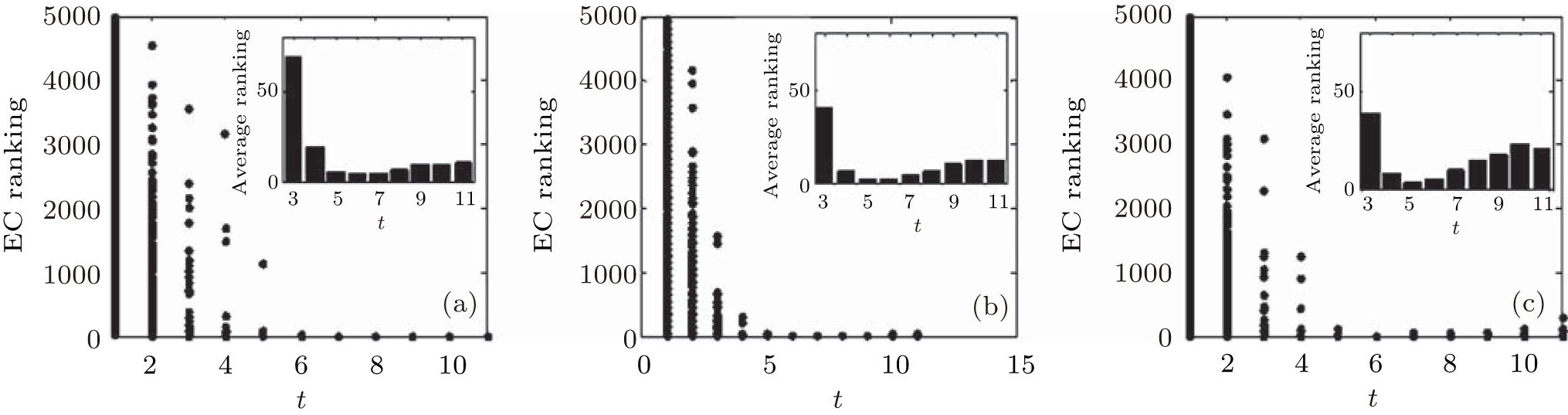 | Fig. 5. Target node rankings and the average ranking of 500 implementations by EC for SF networks with the clustering coefficient C = 0.009 (a), 0.165 (b), and 0.542 (c). |
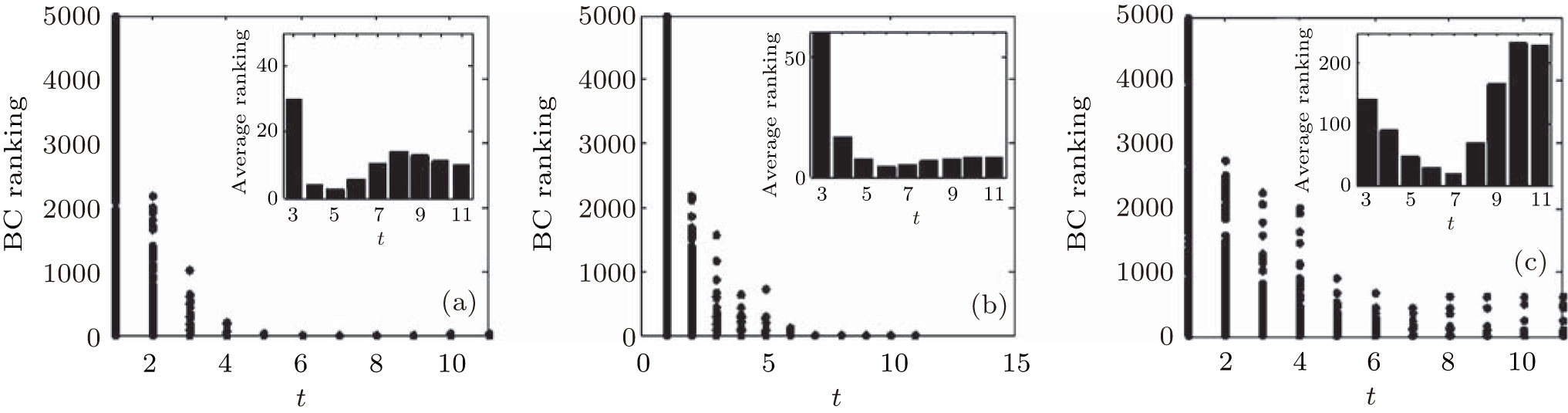 | Fig. 6. Target node rankings and the average ranking of 500 implementations by BC for SF networks with the coefficient of assortativity r = − 0.05 (a), 0.15 (b), and 0.3 (c). |
 | Fig. 7. Target node rankings and the average ranking of 500 implementations by CC for SF networks with the coefficient of assortativity r = − 0.05 (a), 0.15 (b), and 0.3 (c). |
 | Fig. 8. Target node rankings and the average ranking of 500 implementations by DC for SF networks with the coefficient of assortativity r = − 0.05 (a), 0.15 (b), and 0.3 (c). |
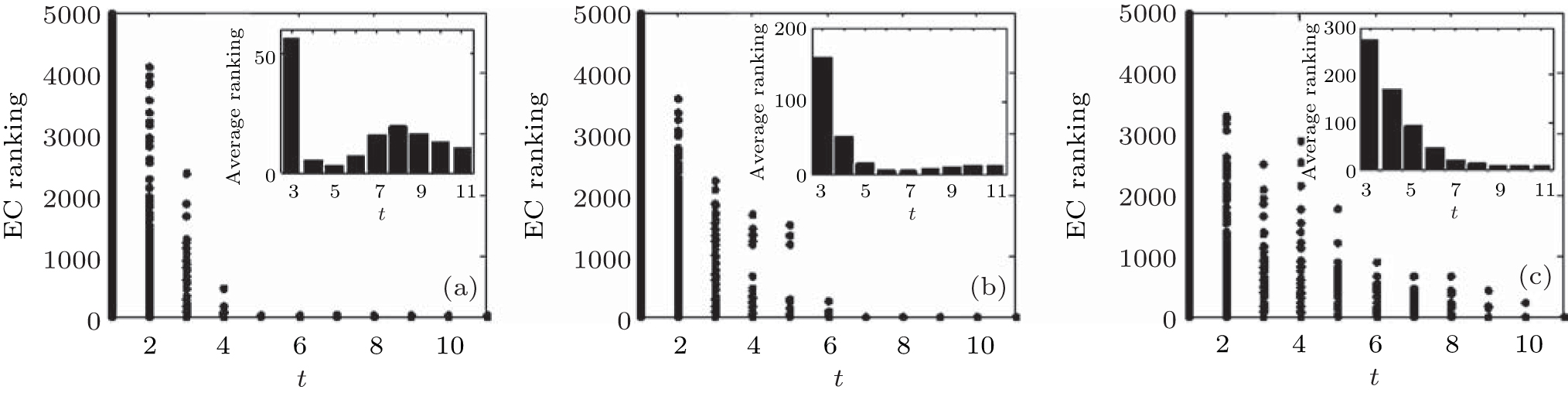 | Fig. 9. Target node rankings and the average ranking of 500 implementations by EC for SF networks with the coefficient of assortativity r = − 0.05 (a), 0.15 (b), and 0.3 (c). |
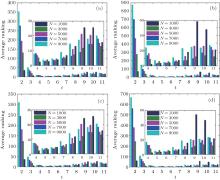
We can see from the figures that the RIM performs well on identifying high-ranking nodes in different networks. Topranking nodes can be identified before the 11th step, and the nodes’ average rankings from the 5th step to the 9th step by different centralities are lower than those in other steps in different network structures, which means that the nodes found from the 5th step to the 9th step are of higher influence. In addition, the experiments in networks with different sizes (Fig. 10) show that the RIM performs well in networks with different sizes.
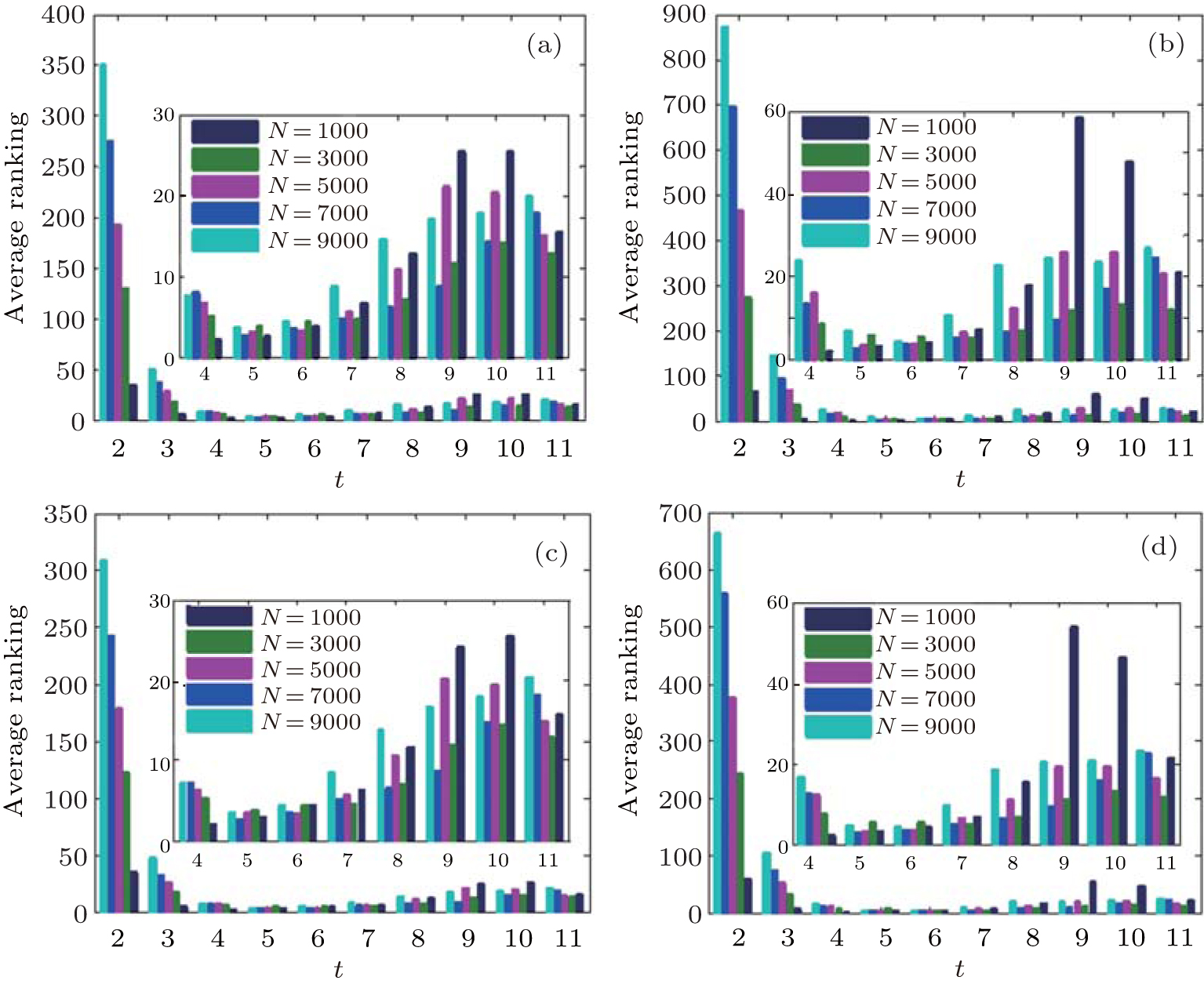 | Fig. 10. Target node average ranking of 500 implementations by four different centralities: (a) BC, (b) CC, (c) DC, and (d) EC, for SF networks with different values of scales N. |
The results in artificial networks show that we can find the highly influential nodes within 10 steps by using the RIM. In each step, only the local information of the node is used, which is more realistic than the ranking measures based on global information. Furthermore, the experiments are also implemented in different real networks, the results of which are shown in Figs. 11– 13. We can see that highly influential nodes can be found within 10 steps, and the nodes’ average rankings from the 4th step to the 8th step by different centralities are lower than those in other steps in different real networks, which means that the nodes found from the 4th step to the 8th step are more influential than other nodes we found.
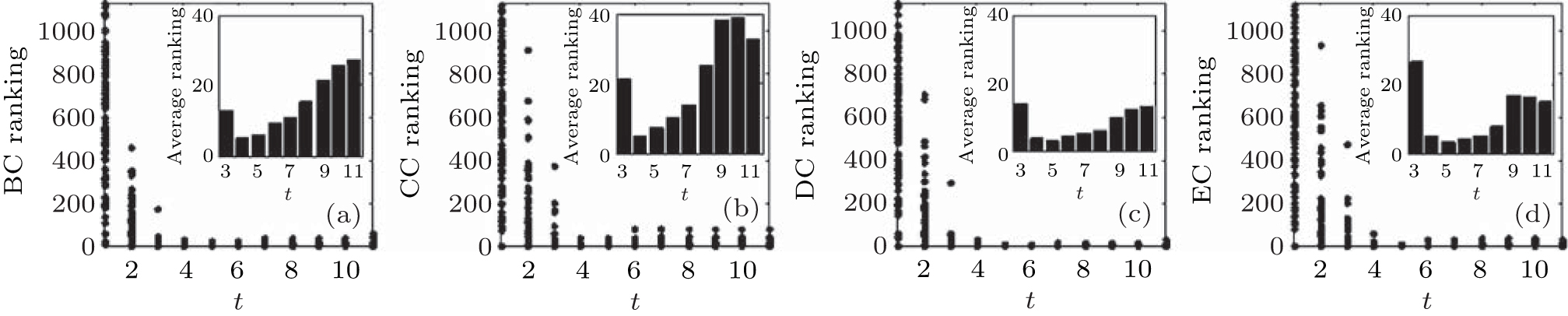 | Fig. 11. Target node rankings and the average ranking of 500 implementations for the Email network by four different centralities:, (a) BC, (b) CC, (c) DC, and (d) EC. |
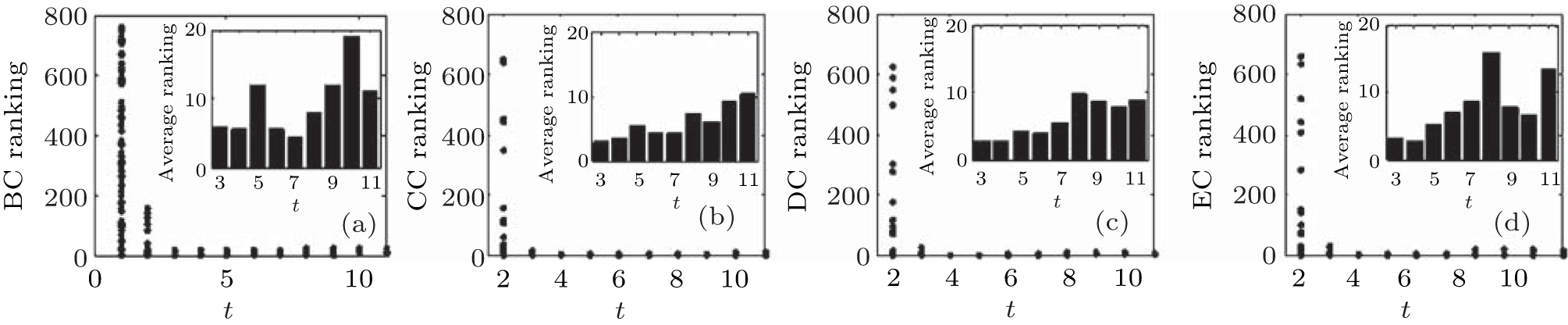 | Fig. 12. Target node rankings and the average ranking of 500 implementations for the Caltech Facebook network by four different centralities: (a) BC, (b) CC, (c) DC, and (d) EC. |
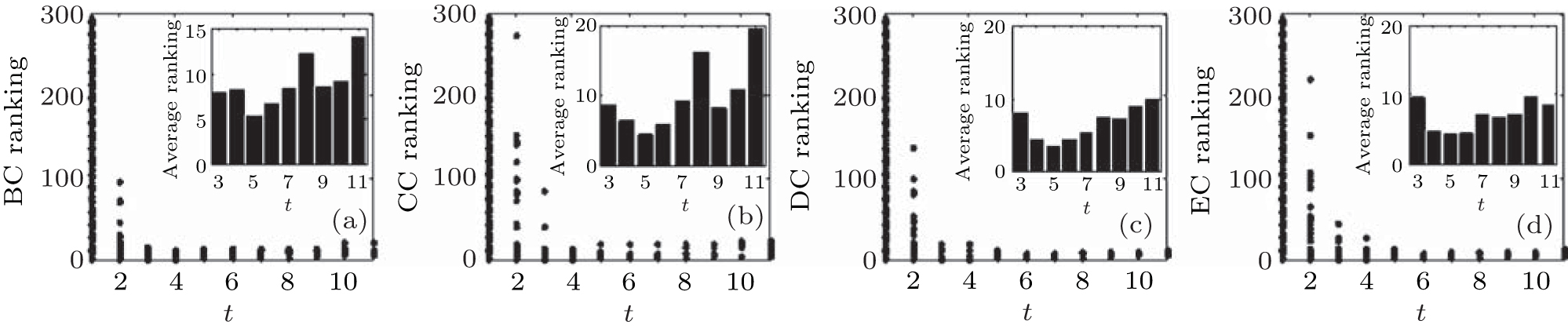 | Fig. 13. Target node rankings and the average ranking of 500 implementations for the Neural network by four different centralities: (a) BC, (b) CC, (c) DC, and (d) EC. |
We can see from Figs. 2– 13 that under different centrality methods, the influences ranked by different centralities are highly related. For example, the high-influence nodes ranked by degree centrality are relatively high influence under other ranking measures. The top-10 ranked nodes by DC and their corresponding ranks by BC, CC, EC are shown in Table 5. Table 5 shows that top-ranking nodes ranked by different centralities are mostly similar.
| Table 5. Top-10 ranked nodes by DC and their corresponding ranks by BC, CC, EC. |
To further evaluate the performance of our method, we use the SIR model to examine the spreading influence of the target nodes. At each step, the susceptible neighbor becomes infected with probability α (here we set α = 0.1). Infected nodes recover with probability β at each step (here we set β = 0.1). To investigate the influence of target nodes found by the RIM, we set these target nodes from the 3rd to the 7th step to be infected initially. By contrast, nodes in the top-5 list by different centrality methods are also treated as infected nodes initially. The ratios of infected nodes to recovered nodes at time t in different artificial networks and real networks, denoted by f (t), are shown in Figs. 14, 15, and 17. In addition, the values of the final number of recovered nodes F(T) in the steady state in networks with different sizes are shown in Fig. 16. Results of Figs. 14– 17 are obtained by averaging over 100 implementations.
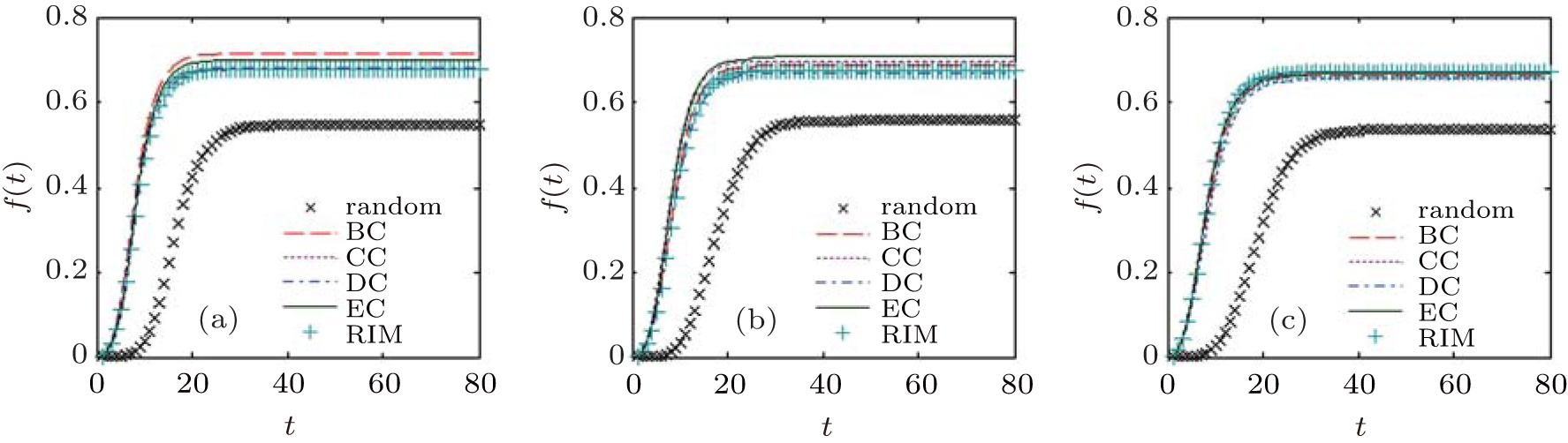 | Fig. 14. Infection intensities of nodes as a function of time, with the initially infected nodes found by RIM, compared with the nodes in the top-5 list obtained by different centralities in SF networks with the clustering coefficient C = 0.009 (a), 0.165 (b), and 0.542 (c). |
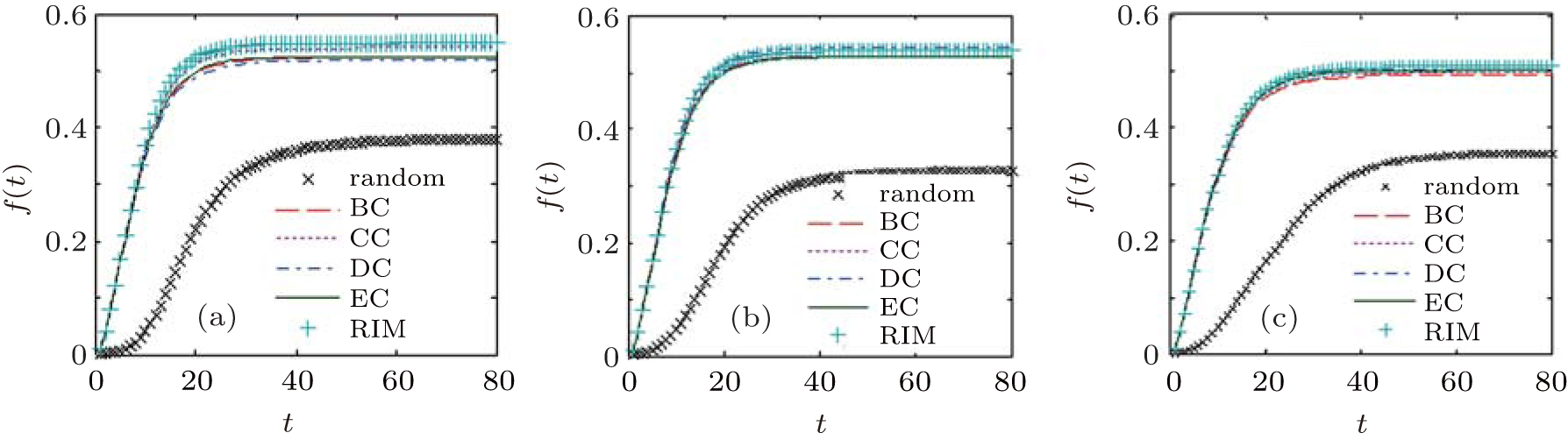 | Fig. 15. Infection intensities of nodes as a function of time, with the initially infected nodes found by RIM, compared with the nodes in the top-5 list obtained by different centralities in SF networks with the coefficient of assortativity r = − 0.1 (a), 0 (b), and 0.2 (c). |
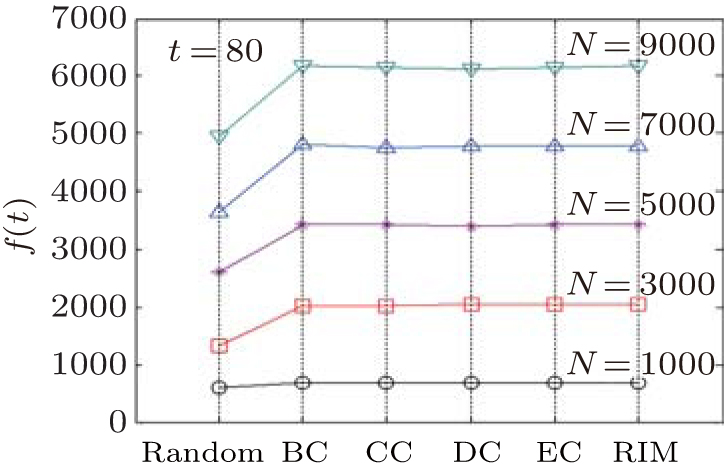 | Fig. 16. Infected numbers of the steady state at time t = 80, with the initially infected nodes found by RIM, compared with the nodes in the top-5 list obtained by different centralities in SF networks with different values of size N of networks. |
 | Fig. 17. Infection intensities of nodes as a function of time, with the initially infected nodes found by RIM, compared with the nodes in the top-5 list obtained by different centralities in real networks, i.e., (a) Caltech Facebook network, (b) email network, and (c) neural network. |
In Figs. 14– 17, we can see that the curves under different centrality methods are similar to ones under RIM, which means that the nodes found by RIM have almost the same effectiveness on epidemic spreading in different networks, compared with those appearing in the top-5 node list obtained by different centralities. Also we can see that the nodes found by RIM lead to faster and wider spread than in the case that initial spreaders are randomly chosen.
Considering the uncertainties of network scale, topologies and the timeliness of dynamic behaviors in real networks, we propose a rapid identifying method (RIM) to find the fraction of highly influential nodes instead of ranking all nodes. Four centrality methods are used to verify the effectiveness of RIM. Furthermore, we use the SIR model to evaluate the performance of RIM. The experimental results in different networks (artificial networks and real networks) show that our method performs well on identifying highly influential nodes.
Besides the node’ s degree, some other local properties of the node, such as the clustering coefficient, can also serve as the measuring standard of node influence. In particular, it may be effective in the small-world network and random network, which will be studied in our future work.
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
|
| 9 |
|
| 10 |
|
| 11 |
|
| 12 |
|
| 13 |
|
| 14 |
|
| 15 |
|
| 16 |
|
| 17 |
|
| 18 |
|
| 19 |
|
| 20 |
|
| 21 |
|
| 22 |
|
| 23 |
|
| 24 |
|
| 25 |
|
| 26 |
|
| 27 |
|
| 28 |
|
| 29 |
|
| 30 |
|
| 31 |
|
| 32 |
|